Panel Showcase
Alessandro Guida
European Institute of Oncology, MilanIn this analysis we will simulate a basket clinical trial run on patients affected by 3 diseases: breast, lung and gastric cancer. Samples will be collected and sequencing with Next-generation sequencing technology. Patients will be assigned to treatment groups based on the genomic characterization. The panel design is based on a recent publication that defines the guidelines for precision medicine and the genes that should be included into diagnostic NGS assays for the previously indicated tumor type.
Consensus on precision medicine for metastatic cancers: a report from the MAP conference C.
BASKET TRIAL PANEL SHOWCASE
OBJECTIVES
The objective of this analysis is to:
- Simulate the panel “detected fraction” (defined as the number of patients with at least one alteration detectable by the genomic panel) in different tumor types.
- Simulate a genomic driven clinical trial: As we might risk to have “unbalanced” group treatment, we would like to know in advance the patient allocation frequency to different treatment arms based on the alteration frequency in the cancer population;
- Estimate the number of patients needed to be screened;
- Optimize the size of the panel and therefore reduce experimental cost;
- As last, illustrate the usage of PTD in a concrete showcase context.
Initial assumption
The panel is designed based on the guidelines indicated in the recent publication:
Consensus on precision medicine for metastatic cancers: a report from the MAP conference C.
We had to make some adjustments and interpretations in order to fit the guidelines into a panel design that would be input by the PTD package.
Gene name adoption
PTD requires gene names to be written in HGNC format. Since the software will download data from different web databases, we need to make sure that gene names follow the international convention. While scanning the paper, we noticed that the following genes were encoded in the paper with names that do not match the HGNC standards. We have therefore apply the following interpretations and corrections:
| Paper annotation | Conversion for the analysis |
|---|---|
NTKR (Possible typo?) |
NTRK1, NTRK2, NTRK3 |
NTRK |
NTRK1, NTRK2, NTRK3 |
Moreover, the paper states that for gastric tumor, MSI should be tested. We can infer this information testing the following genes: MLH3, MLH1, MSX1, MSX2
Gene alterations
In this analysis we will only consider the following alteration:
- SNV
- CNA
- Fusions (only for lung tumor since they were selected to be lung cancer specific alteration)
Changes in expression are not included in this analysis.
Drug Treatment
For demonstrative purposes we are simulating a clinical trial by associating altered genes to “general drug families” as a possible treatment.
Tumor types
The paper we are basing our work on, defines the guidelines for 3 diseases:
- Breast cancer;
- Lung cancer;
- Gastric Cancer;
We need to convert these diseases into tumor ID compatible with the TCGA standard. The conversion is applied as follows:
| Publication definition | TCGA tumor ID conversion adopted |
|---|---|
| Breast Cancer | brca (Breast invasive carcinoma) |
| Lung Cancer | luad (Lung adenocarcinoma) |
| Lung Cancer | lusc (Lung squamous cell carcinoma) |
| Gastric Cancer | stad (Stomach adenocarcinoma) |
| Gastric Cancer | coadread (colon) |
We are making the assumption that the cancer population of reference is composed entirely and uniquely by this cancer subtypes
# Define tumor types
tumor_types <- c("brca", "luad", "lusc", "stad", "coadread")Sampling Populations
In this section, we will attempt to estimate the sample size of each cancer type in a population of reference. For this simulation we will use a population of reference sampled according to the statistics published by seer.cancer.gov
- http://seer.cancer.gov/csr/1975_2013/results_single/sect_a_table.01_2pgs.pdf
- local copy of the file extra_docs/sect_a_table.01_2pgs.pdf
Seer reports that, between 2009 and 2013 the tumor population amounted to:
- Breast cancer: 306665 people;
- Lung cancer: 256350 people;
- Gastric cancer:
- Stomach cancer: 33174 people;
- Colon and rectum cancer: 185758 people;
Breast carcinoma
Frequency of the population is adjusted by Breast carcinoma according to the following table sect_04_table.25_2pgs.pdf:
- brca: 99.4%
Lung subtypes
Frequency of the population is adjusted by lung tumor subtypes according to online link, local file:
- Lung Adenocarcinoma: 45% of lung population
- Lung squamous and transitional cells: 23.0% of lung population
Gastric subtypes
Frequency of the population is adjusted by stomach tumor subtypes according to online link, local copy
- Stad: 82%
Frequency of the colon cancer are adjusted according to online link, local file
- Coadread: 92.8%
We will therefore use these statistics as our population of reference using the following approximations:
set.seed(7)
# assign number of patients
luad_tot = ceiling(256350*0.45) #adjustement coefficient specific to the % of subtype tumor in a lung cancer population
lusc_tot = ceiling(256350*0.23) #adjustement coefficient
stad_tot = ceiling(33174*0.82) #adjustement coefficient
coadread_tot = ceiling(185758*0.928) #adjustement coefficient
brca_tot = ceiling(306665 * 0.994)
# total
all_tot = brca_tot+luad_tot+lusc_tot+stad_tot+coadread_tot
# calculate frequencies
brca_freq = brca_tot/all_tot
luad_freq = luad_tot/all_tot
lusc_freq = lusc_tot/all_tot
stad_freq = stad_tot/all_tot
coadread_freq = coadread_tot/all_tot| TCGA tumor ID | population considered | frequency |
|---|---|---|
| brca | 304826 |
0.449111 |
| luad | 115358 |
0.169961 |
| lusc | 58961 |
0.0868693 |
| stad | 27203 |
0.0400791 |
| coadread | 172384 |
0.2539795 |
ANALYSIS
In the following phases we will proceed by designing the panel and visualizing its performance through different types of plots.
Design phase
First step is to create the panel design using an excel file according to the standards of the package. The panel design is loaded into R and can be previewed in the table below.
library(DT)
library(knitr)
library(ggplot2)
library(readxl)
library(PrecisionTrialDrawer)
# Helper functions
`%++%` <- function(a,b) paste0(c(a,b), collapse = " ")
# calculate the right confidence interval of a proportion
rightCIprop <- function(p, sample_size){
se <- sqrt( p*(1 - p)/sample_size)
right <- p + 1.96*se + 0.5/sample_size
if (right > 1) right <- 1
return(right)
}
# calculate the left confidence interval of a proportion
leftCIprop <- function(p, sample_size){
se <- sqrt( p*(1 - p)/sample_size)
left <- p - 1.96*se - 0.5/sample_size
if (left < 0) left <- 0
return(left)
}
# Import excel file in R
panel_design <- readxl::read_xlsx("version_6.0/Tables/tb1_PTD_panel_showcase.xlsx")
# preview the input table
datatable(panel_design)We can now run the main function of the R package and:
- Import the panel design into a CancerPanel object;
- download Alteration information for the drug types of interest;
- Adapt the alteration information to the CancerPanel design;
# 1. Create the panel Object using PTD package - DESIGN PHASE
PTD_panel <- newCancerPanel(panel_design)
# 2. DOWNLOAD PHASE
PTD_panel <- getAlterations(PTD_panel, tumor_type=tumor_types)
# 3. SIMULATION PHASE
PTD_panel <- subsetAlterations(PTD_panel)
#save a backup copy to speed up future analysis
saveRDS(PTD_panel, file="version_6.0/Temp/PTD_panel.rds")At this point PTD_panel contains all the information we need to visualize the panel performance.
Filter non pathogenic mutations
Remove NON pathogenic mutation fetched from cosmic dataset (01-05-2017).
Cosmic mutations where downloaded from the cosmic dataset on the 18-05-2017.
# save the number of entries in the TCGA beofere any filtering
TCGA_original_number <- nrow(unique(PTD_panel@dataFull$mutations$data))
# Clean TCGA popualation running a cosmic filter
cosmic <- readr::read_csv("version_6.0/external_resources/cosmic_df_PTD.csv")## Warning: Missing column names filled in: 'X1' [1]## Parsed with column specification:
## cols(
## X1 = col_integer(),
## Position = col_integer(),
## CDS.Mutation = col_character(),
## AA.Mutation = col_character(),
## `Mutation ID (COSM)` = col_integer(),
## Count = col_integer(),
## Type = col_character(),
## gene = col_character()
## )cosmic_df <- data.frame(gene_symbol = cosmic$gene
, amino_acid_change = sub("^p." , "" , cosmic$AA.Mutation)
, stringsAsFactors = FALSE)
PTD_panel <- filterMutations(PTD_panel , filtered = cosmic_df , mode = "keep")## Subsetting fusions...## Subsetting mutations...## Subsetting copynumber...- Filtering out **
36.26% ** of the TCGA original SNVs.
Exclude predefined genomic regions from the simulation
A useful feature of PTD is the possibility to remove with precision certain genomic regions from the study simulation. This is particularly relevant in the clinical routing as, we might be interested for example only in a subset of mutation in a particular portion of a gene. For example, EGFR T790M and PIK3CA exon 20 mutations are associated with resistance to 1st generation EGFR inhibitors. In this analysis we will model the SNV mutations in PIK3CA excluding SNV located in exon 20, as well as exclusding EGFR T790M.
This can be achieved through the shiny app web interfance using the function panelOptimizer or programmatically, by applying a genomic filter:
# PIK3CA, Exon20 on the hg19 genome assembly is mapped at the
# coordinates: chr3: 178,866,311-178,957,881
# ==============================================================================
# Let's create a bed file with the genomic region to exclude
bed <- data.frame(chr = "chr3"
, start = 178948013
, end = 178948164
, stringsAsFactors = FALSE)
PTD_panel <- filterMutations(PTD_panel , bed = bed , mode = "exclude")## Subsetting fusions...## Subsetting mutations...## Subsetting copynumber...# EGFR T790M can be removed by specifing the mutations using the a.a. format
# ==============================================================================
toberemoved <- data.frame(gene_symbol = "EGFR"
, amino_acid_change = "T790M"
)
PTD_panel <- filterMutations(PTD_panel , filtered = toberemoved, mode = "exclude")## Subsetting fusions...## Subsetting mutations...## Subsetting copynumber...# for help and more details see ?filterMutationsAdjust CNA threshold to be clinically relevant
CNA data provided by cBioPortal reports the final step in CNV calls from GISTIC pipeline (CIT). CNVs are reported as either
- -2: deletion
- -1: shallow deletion
- 0: normal
- 1: shallow amplification
- 2: amplification
Values of -2 or 2 are considered alterations, while the rest is considered as normal copies. For research purposes, these criteria are very useful to discover new potential gene copies alterations but a clinical setting requires stronger evidence for a call, especially in case of amplification. The SHIVA trial protocol, for instance, in order to consider clinically relevant a AKT amplification, it requires at least the presence of 5-6 copies. A similar granularity is not possible with the final GISTIC results but it can be obtained up to a certain degree using the original data provided by the GDAC Firehose (the same used by cBioPortal).
We downloaded GISTIC run 2016_01_28 all_thresholded.by_genes.txt files for 32 tumor types and normalized the segmented value for each patient by their respective thresholds. Each sample of the TCGA cohort has a deletion and amplification call threshold calculated according to estimated ploidy and purity of the original sample. For example, a low purity sample will have lower threshold for calling a CNV compared to a 100% purity sample because of the normal diploid cells contamination. These thresholds represents the points were an amplification (2) or deletion (-2) are called.
This normalization reformats the data as absolute number of copies in the following way:
- 0-1: deletion
- 1.1: shallow deletion
- 2: normal
- 2.9: shallow amplification
- 3-Inf: amplification
While data from 1.1 to 2.9 are the same as before (considered normal on default), now 1 is the point of -2 deletion and 3 the point of +2 amplification. We have now the full spectrum of amplification from > 3 that can be used to fine-tune the clinically relevant threshold (4, 5 ,6 copies for example).
# SETTINGS
# ==============================================================================
# DEFINE GENES: define genes we are interested for the CNA analysis
CNA_genes <- PTD_panel@arguments$panel %>%
dplyr::filter(alteration == "CNA") %>%
dplyr::select(gene_symbol) %>%
.[[1]]
# PATH: set global variable with the path to.rds files with CNA raw data
PATH_2CNA_FILES <- "version_6.0/Temp/cna_firehose_rds/"
# helper function that reads in a firehose RDS file, filters by gene, and apply the threshold configured
# ==============================================================================
get_cna_long <- function(tumor_types, PATH_2CNA_FILES, genes_chr, del_thr, amp_thr){
# CHECKS
# --------------------------------------------------------------------------------
# check that PATH actually leads to a dir
if(!dir.exists(PATH_2CNA_FILES)){ stop("path to a dir that cannot be found")}
# Check that all the files are found for each tumor type required in the analysis
input_lgl <- purrr::map_lgl(tumor_types
, ~ file.exists(file.path(PATH_2CNA_FILES
, paste0(toupper(.) , "_PTD.rds")
)
)
)
if(!all(input_lgl)){
stop(paste("Files for some of the tumor types where not found:"
, tumor_types[-which(input_lgl)])
)
}
# Checks
if(!is.character(tumor_types) | is.null(tumor_types) | length(tumor_types) ==0){
stop(paste("Tumor type is not confirm", tumor_types))
}
# Define an internal function to do the job
# -------------------------------------------------------------------------------
get_CNA_long_onetumor <- function(one_tumor, PATH_2CNA_FILES, genes_chr, del_thr, amp_thr){
# read in CNA file
# myfile <- readRDS(paste0(PATH_2CNA_FILES, toupper(one_tumor) , "_PTD.rds"))
# if(!file.exists(myfile)){
# message(myfile)
# return(NULL)
# }
# mat <- tryCatch(readRDS(myfile) , error = function(e) stop(myfile))
mat <- readRDS(file.path(PATH_2CNA_FILES, paste0(toupper(one_tumor) , "_PTD.rds")))
# extract Patients
pats <- colnames(mat)
# Filter for gene of interest
mat <- mat[ genes_chr , ]
# Melt and adjust
output <- reshape2::melt(mat , value.name = "CNAvalue")
colnames(output) <- c("gene_symbol" , "case_id" , "CNAvalue")
output$tumor_type <- one_tumor
# Choose cutoff values
# -----------------------------------------------------------------------------
# With default threshold data are now like this:
# [0 , 1.1) "deletion"
# 1.1 "shallow deletion"
# 2 "normal"
# 2.9 "shallow amplification"
# (2.9 , Inf] "amplification"
output$CNA <- ifelse( output$CNAvalue <del_thr
, "deletion"
, ifelse(output$CNAvalue > amp_thr , "amplification" , "normal"))
# select
output <- output %>%
dplyr::select(gene_symbol , CNA , case_id , tumor_type, CNAvalue) %>%
dplyr::mutate(gene_symbol = as.character(gene_symbol)) %>%
dplyr::mutate(case_id = as.character(case_id))
return(output)
}
# Main body of the function
# -----------------------------------------------------------------------------
cna_long_df <- purrr::map(tumor_types
, ~ get_CNA_long_onetumor(.
, PATH_2CNA_FILES
, genes_chr
, del_thr
, amp_thr
)
) %>%
dplyr::bind_rows()
return(cna_long_df)
}
# RUN MAIN FUNCTION
# ==============================================================================
cna_long_df <- get_cna_long(tumor_types
, PATH_2CNA_FILES
, CNA_genes
, del_thr = 1.1
, amp_thr = 4
)
# Create Sample
# ----------------------
# get list of tumors
tumor_chr <- cna_long_df$tumor_type %>%
unique %>%
as.character
# prepare funtion to extract sample names for each tumor
sampleXtumor <- function(x, df){
df %>%
dplyr::select(case_id, tumor_type) %>%
dplyr::filter(tumor_type %in% x) %>% .[["case_id"]] %>%
as.character() %>%
unique()
}
# Extract samples for each tumors
Samples <- purrr::map(tumor_chr, ~ sampleXtumor(., df=cna_long_df))
names(Samples) <- tumor_chr
# Check if there are problems.
testthat::expect_equal(length(unlist(Samples)), length(unique(cna_long_df$case_id)))
# Create list element for CNA for the DataFull argument of the panel (panel@DataFull)
# ==============================================================================
copynumber <- list( data = data.frame(cna_long_df)
, Samples = Samples)
# Preview changes before committing
PTD_cna_pop_comparison <- purrr::map2(
.x = list( PTD_panel@dataFull$copynumber$Samples, copynumber$Samples )
, .y = list( "TCGA", "Firehose" )
, .f = ~ purrr::map_int(.x, length) %>%
data.frame(n_patients = .) %>%
tibble::rownames_to_column("tumor_type") %>%
dplyr::mutate(source = .y)
) %>%
dplyr::bind_rows() %>%
ggplot(aes(tumor_type, n_patients, fill=source)) +
geom_bar(stat="identity", position= position_dodge()) +
coord_flip() +
ggtitle("number of patients in the CNA datasets")
# Preview
PTD_cna_pop_comparison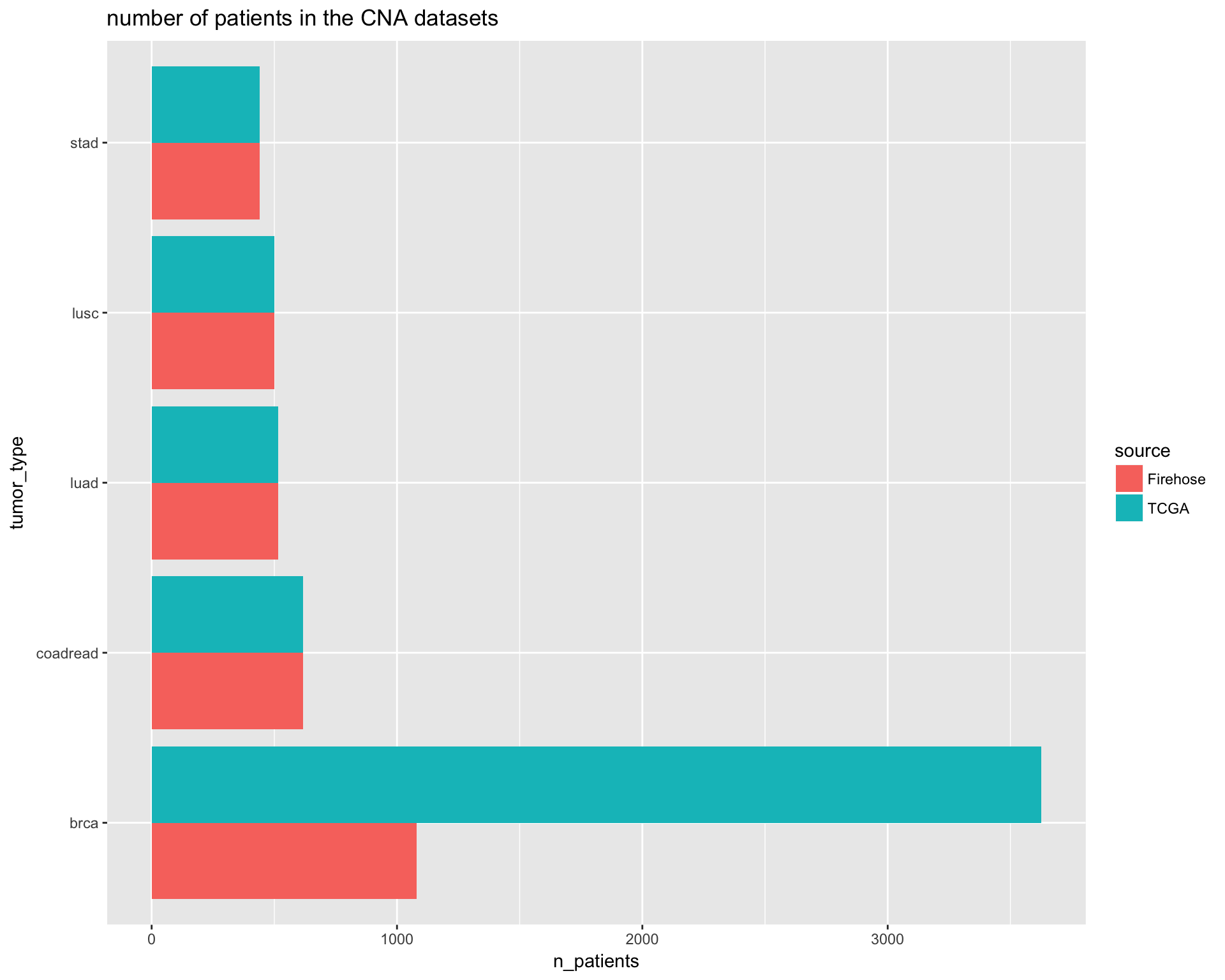
apply changes to the TCGA population object.
# Apply changes
PTD_panel@dataFull$copynumber <- copynumber
PTD_panel <- subsetAlterations(PTD_panel)## Subsetting fusions...## Subsetting mutations...## Subsetting copynumber...Visualisation and Simulations of the panel performance
In this section we will start running some of the visualization functions to investigate how well the panel would perform in different conditions. Before starting out investigation we want to visualize the sample number by tumor type to keep in consideration any sampling bias due to the population of origin. This bias can be corrected using the option tumor.wieights or tumor.freqs.
The following table shows the number of samples (y-axis) collected for this analysis for each tumor type considered.
coverageStackPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, var="tumor_type", noPlot=TRUE)$Samples %>%
data.frame(Samples=.) %>%
tibble::rownames_to_column("tumor_type") %>%
knitr::kable()| tumor_type | Samples |
|---|---|
| brca | 1080 |
| coadread | 220 |
| luad | 516 |
| lusc | 501 |
| stad | 441 |
| all_tumors | 2758 |
Let’s export the data and make a summary table to resume differences in populations:
# get data for table
tcga_pop <- coverageStackPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, var="tumor_type"
, noPlot=TRUE)
# calculate frequencies
tcga_freqs <- tcga_pop$Samples[-length(tcga_pop$Samples)] / tcga_pop$Samples["all_tumors"]
# make it into a df
population_df <- data.frame(tumor=c("brca", "luad", "lusc", "stad", "coadread")
, seer=c(brca_freq, luad_freq, lusc_freq, stad_freq, coadread_freq)
, tcga = c(tcga_freqs["brca"], tcga_freqs["luad"], tcga_freqs["lusc"], tcga_freqs["stad"], tcga_freqs["coadread"])
)
# barplot, with only the genes in the panel
population_df %>%
tidyr::gather(Population, Frequency, seer:tcga) %>%
ggplot(aes(x=Population, y=Frequency, fill=tumor)) +
geom_bar(stat="identity") +
facet_grid(tumor ~ ., space="free", scales="free") +
ggtitle("Comparison of the initial population composition") +
coord_flip()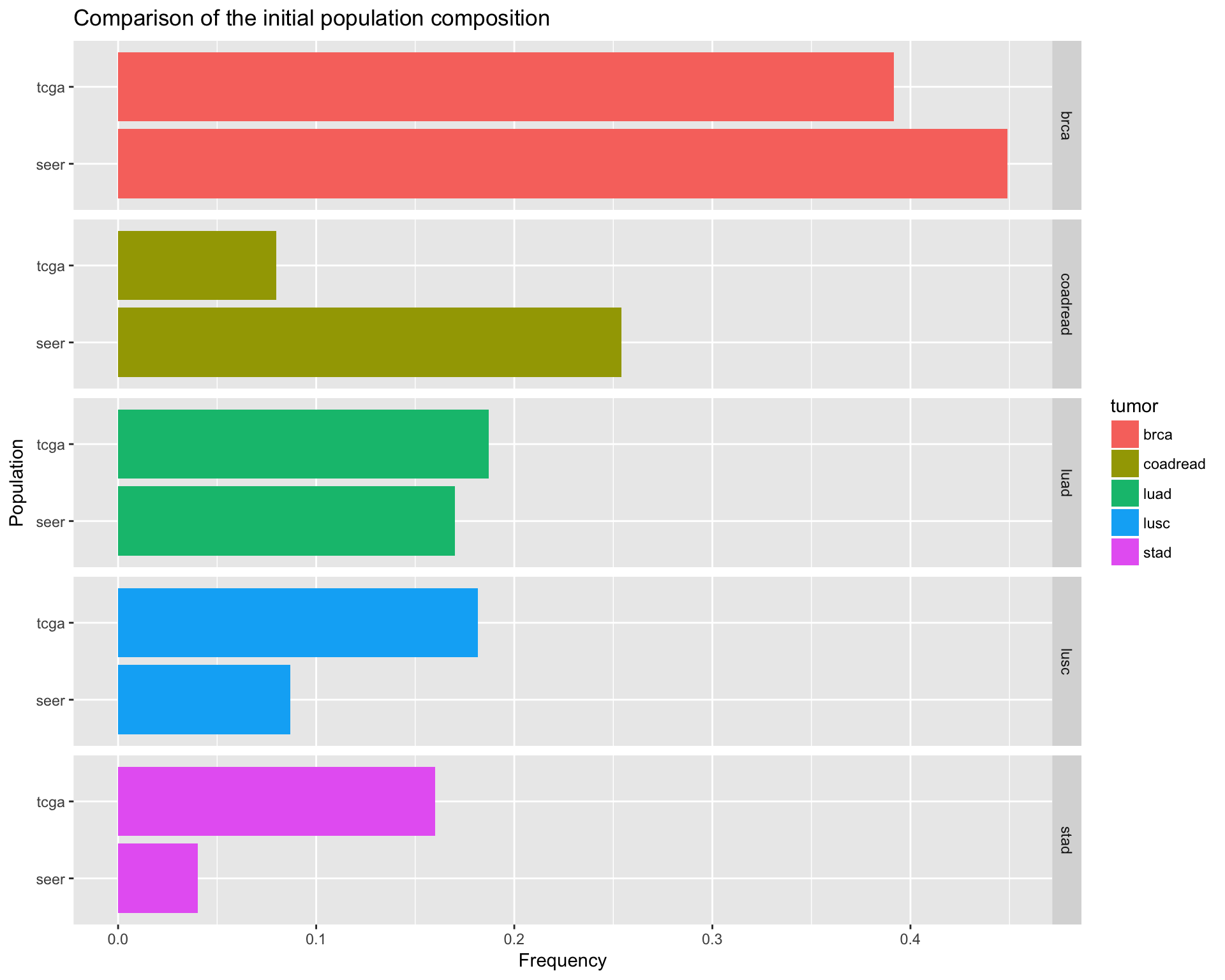
library(svglite)
ggsave(filename="version_6.0/Figures/fig2A.svg", plot=last_plot(), device = "svg")## Saving 10 x 8 in imageComparison table between SEER initial population and TCGA initial population
| TCGA tumor ID | Seer population considered | Seer frequency 1 | TCGA initial population | TCGA sample frequency 2 |
|---|---|---|---|---|
| brca | 3049 |
0.449111 |
1080 |
0.3915881 |
| luad | 1154 |
0.169961 |
516 |
0.1870921 |
| lusc | 590 |
0.0868693 |
501 |
0.1816534 |
| stad | 273 |
0.0400791 |
441 |
0.1598985 |
| coadread | 1724 |
0.2539795 |
220 |
0.0797679 |
Fusion detection in Lung cancer
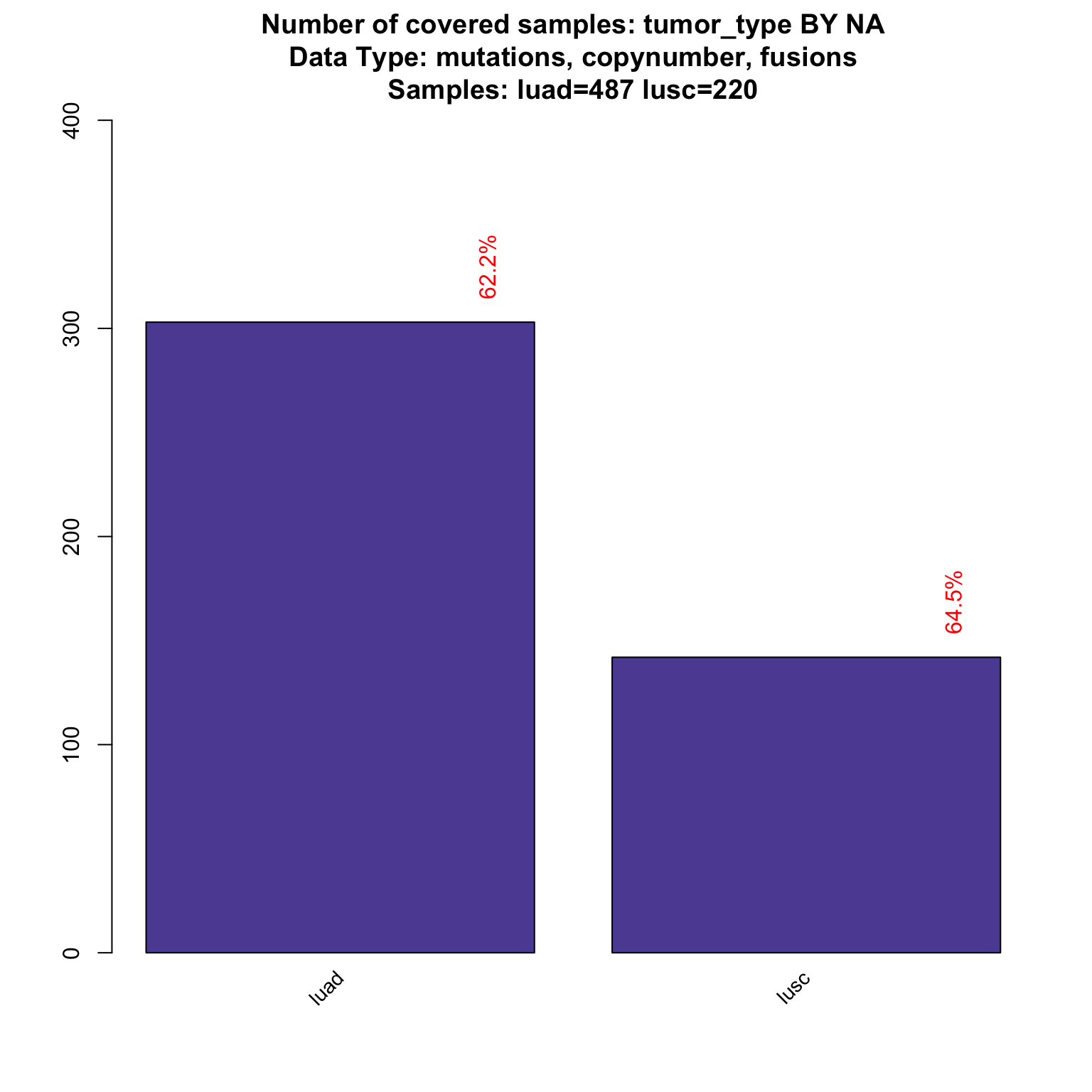
The previous plot does not include fusions, as the fusion in the panel are specific to the lung tumor. If we want to visualize the number of samples with available information for mutations, copynumber and fusions (each patients will have information for each category).
coverageStackPlot(PTD_panel
, alterationType=c("mutations" , "copynumber", "fusions")
, var="tumor_type"
, tumor_type = c("luad", "lusc")
)
Panel detected fraction in the overall population
One common question that is often considered when trying to design custom target enrichment panel, is the percentage of the population that would be “captured” by the design of the panel. The following plot shows the number of alteration (x-axis) found in the sample (patient) population (y-axis). The panel detected fraction can be defined as the number of patients with at least one alteration detectable by the genomic panel. In this simulation we are interested in visualizing the detected fraction in a population background composed by patients from breast, lung, and gastric cancer. For simplicity fusion information are not included in the analysis.
coveragePlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
# adjust population distribution by applying a weighted resampling
, tumor.freqs = c(brca=brca_freq
, luad=luad_freq
, lusc=lusc_freq
, stad = stad_freq
, coadread = coadread_freq
)
)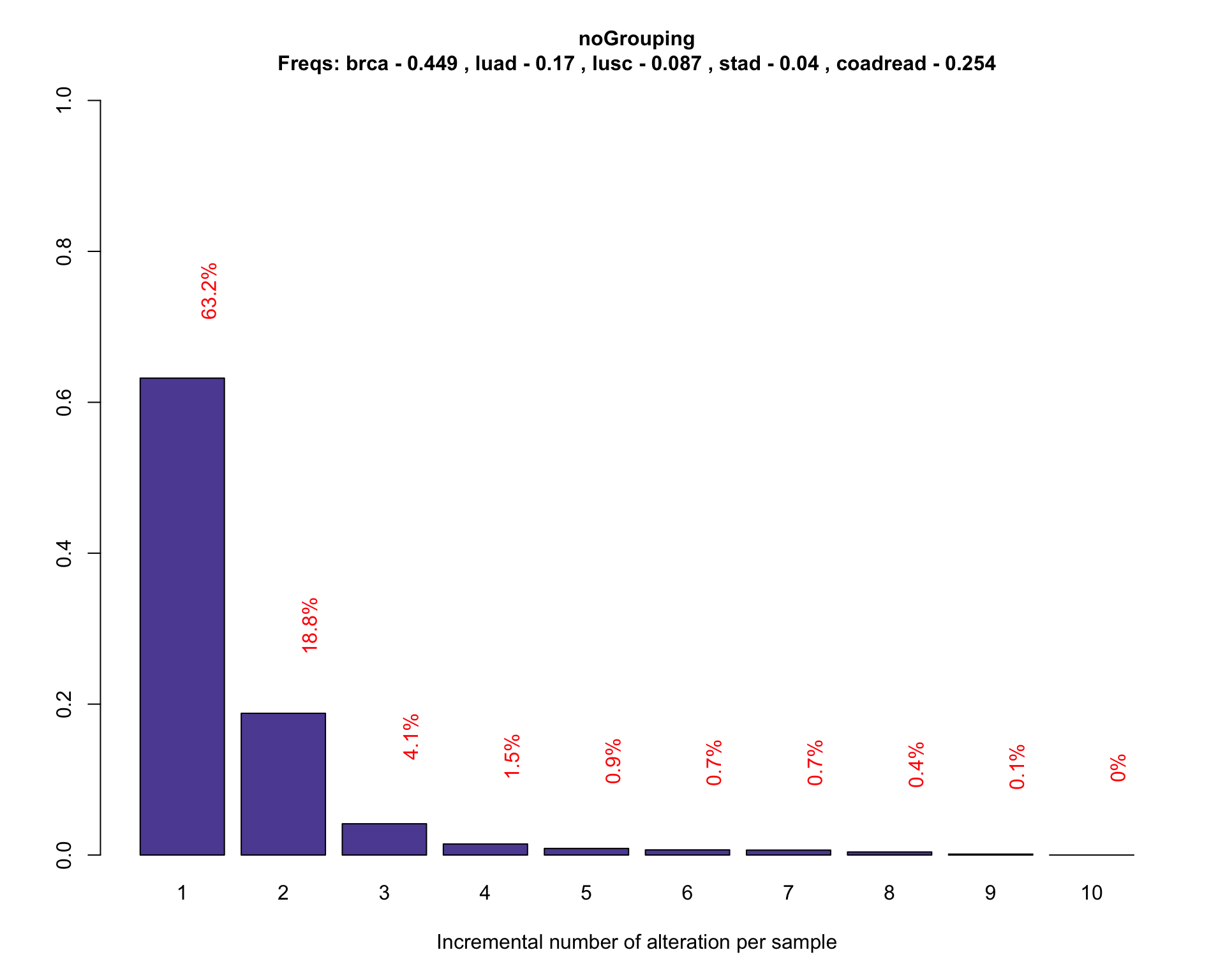
Simulate the panel performance with a weighted resampling simulation run 200 times.
The previous plot shows the percentage of patients (y-axis) found to have at least one, two, three, etc, alterations (x-axis). The current design is capable of detecting 0.63% of the population of reference.
Panel detection-power in a tumor type specific population background
In the following plot we want to identify the performance of our panel for each single tumor types starting from out population of reference composed by the 3 cancers groups.
coveragePlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, grouping = "tumor_type"
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
)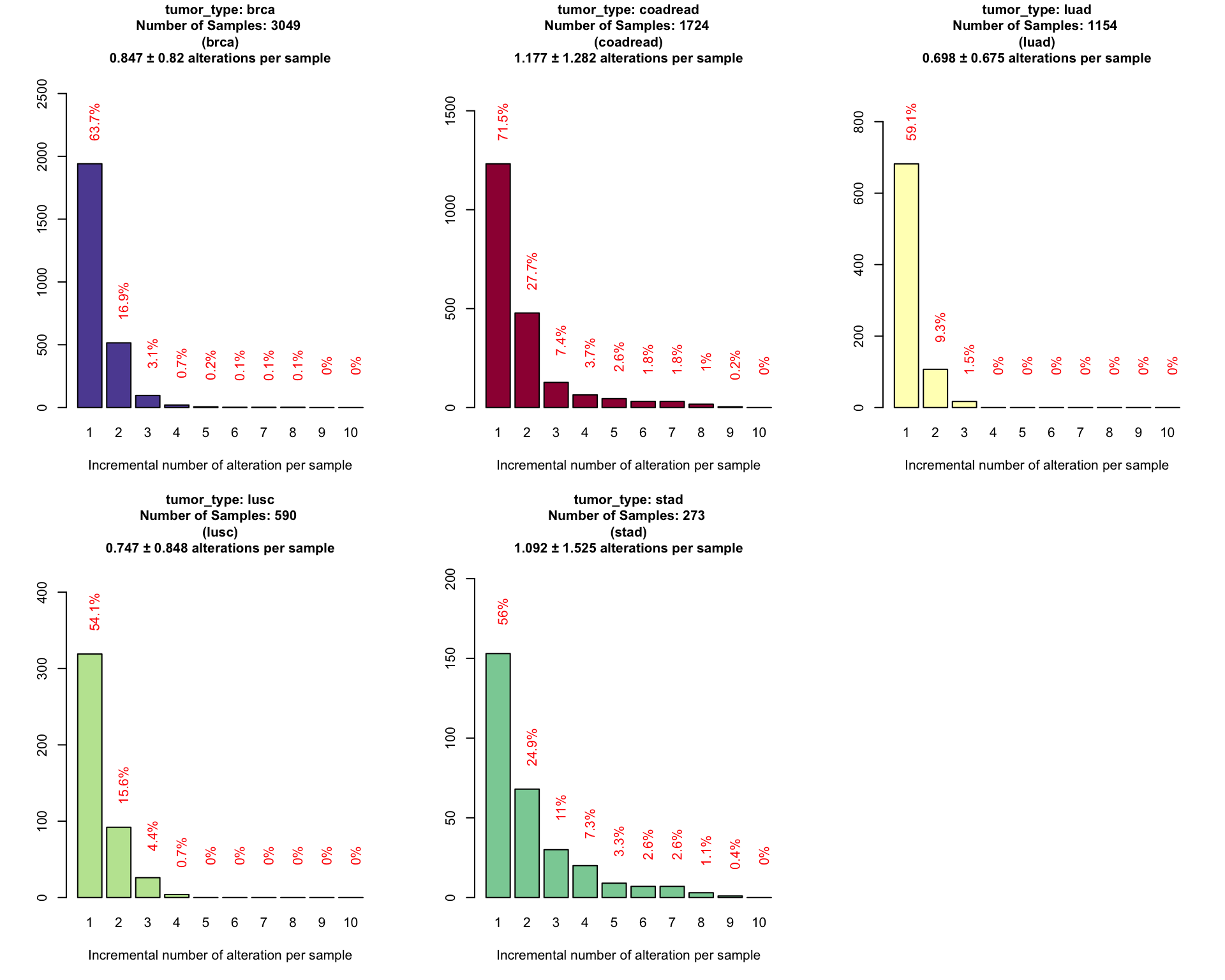
To allow and easy comparison of the detected fraction in different tumor types we have redesign the plots into one unique barplot.
# get data from the panel simulation
dt_power_lt <- coverageStackPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, var="tumor_type"
, noPlot = TRUE
)
# convert to dataframe
dt_power_lt$plottedTable <- data.frame(dt_power_lt$plottedTable)
# calculate frequency
df <- data.frame()
for(i in 1:length(dt_power_lt$plottedTable)){
# find tot. number of samples in matching tumor
index <- which(names(dt_power_lt$Samples) %in% names(dt_power_lt$plottedTable[i]))
if(length(index) != 0 ){
# calculate frequency
# freq <- dt_power_lt$plottedTable[i] / dt_power_lt$Samples[index]
freq <- dt_power_lt$plottedTable[i] / dt_power_lt$Samples["all_tumors"]
}
# export
df <- rbind(df
, data.frame( tumor_id=names(dt_power_lt$Samples[index])
, freq=as.numeric(freq)
, n_samples = dt_power_lt$Samples[index]
)
)
}
# calculate confidence intervals
df$leftCI <- purrr::map2_dbl(df$freq, df$n_samples, .f=leftCIprop)
df$rightCI <- purrr::map2_dbl(df$freq, df$n_samples, .f=rightCIprop)
# sort dataframe
df <- df %>% dplyr::arrange(freq)
# plot
df %>%
ggplot(aes(x=reorder(tumor_id, freq), y=freq*100)) +
geom_bar(stat="identity") +
scale_y_continuous(limits = c(0,50)) +
geom_errorbar(aes( ymax= leftCI*100
, ymin= rightCI*100)
, position=position_dodge(0.9)
, size=0.2
) +
geom_text(aes(x=df$tumor_id
, y=df$freq*100+0.15
, label = sapply(df$freq*100
, function(x) paste(c(round(x, digits=2), "%")
, collapse=" ")
)
) , position = position_dodge(width = 1)
, vjust = 0.5
, hjust = -1.3
) +
coord_flip() +
labs(title="Genomic panel detection-power in different tumor types.") +
ylab(label = "detected fraction indicated as the overall population percentage") +
xlab(label = "tumor type (TCGA ID)")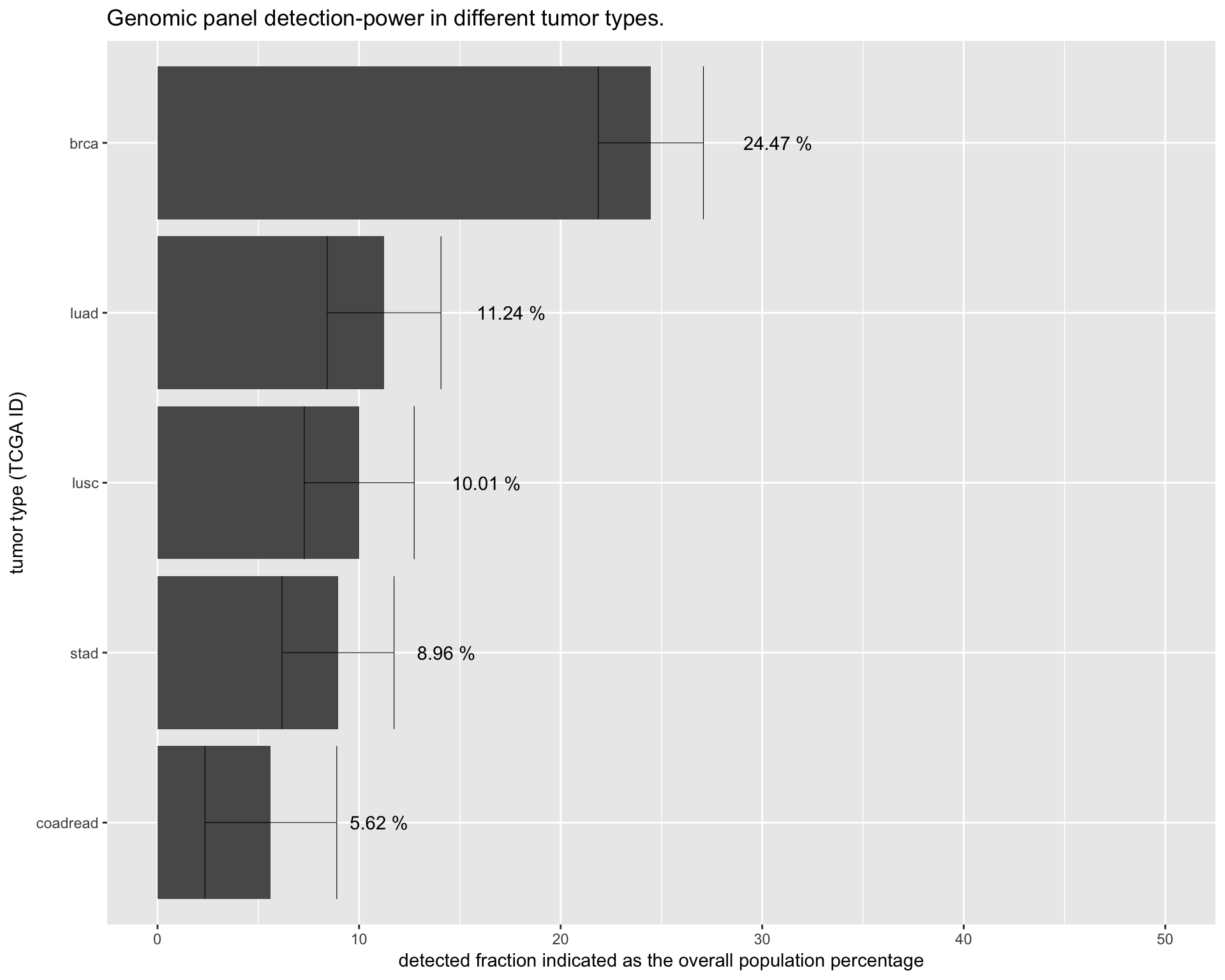
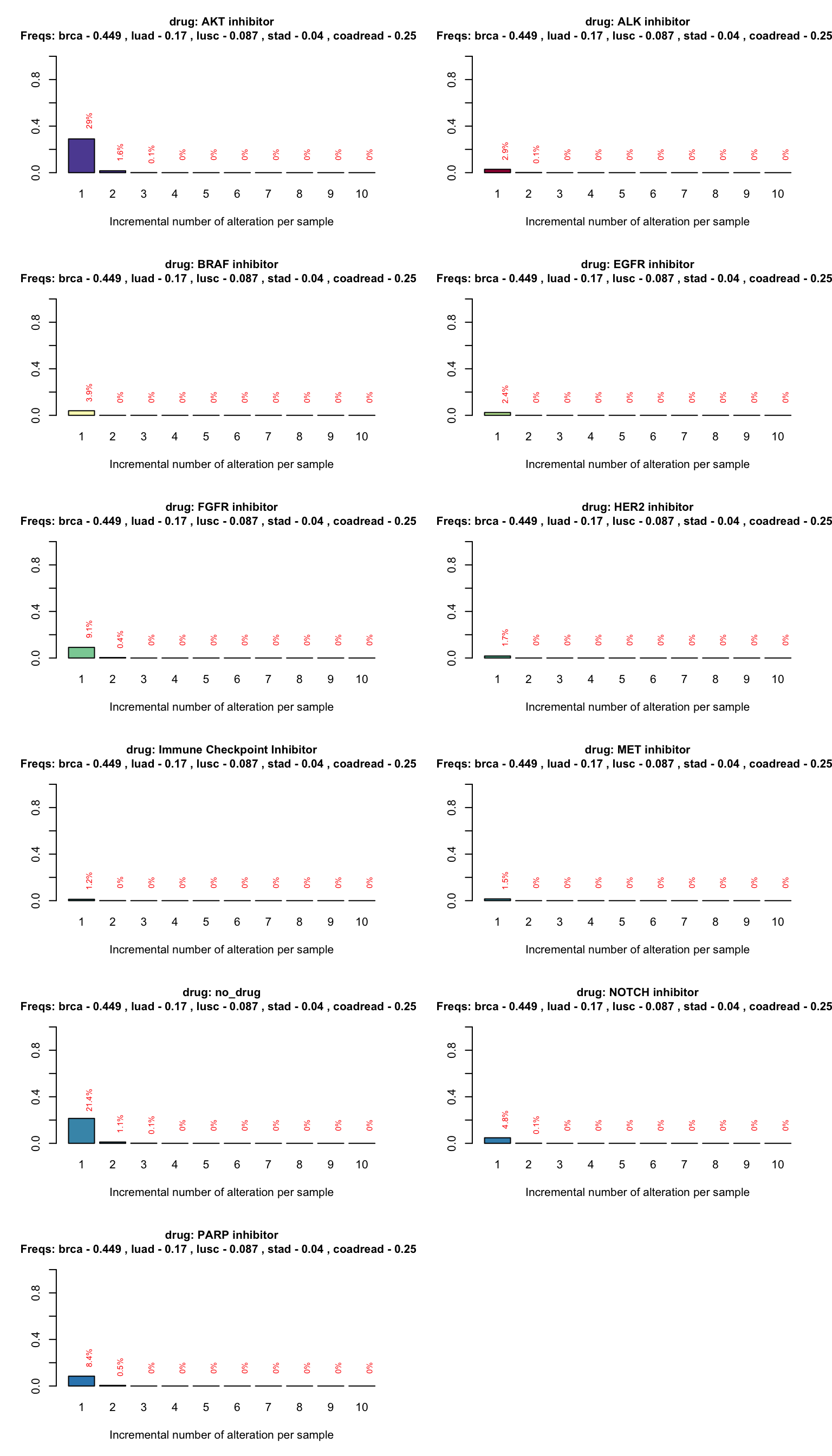
Patient treatment allocation
We can also easily address the issue of the allocation frequency in the different treatment groups. The following plot shows the number of patients with at least one, two or more alterations that can be targeted by each drug in the trial. This is particularly important in clinical trials when you want to predict the maximum number of patients that could be allocated into a drug treatment and identify potential cohorts with few patients allocated.
coveragePlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, grouping="drug"
# adjust population distribution by applying a weighted sampling resampling
, tumor.freqs = c(brca=brca_freq
, luad=luad_freq
, lusc=lusc_freq
, stad = stad_freq
, coadread = coadread_freq
)
, colNum = 2 # number of columns in the plot
, cex.main = 1 # size of the plot title
)
To make it simpler to compare, we will plot the detected fraction for each drug type in a unique plot. The following code will put all the previous plot together in one unique barplot.
# get data from the panel simulation
drug_df <- coveragePlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, grouping="drug"
# adjust population distribution by applying a weighted resampling
, tumor.freqs = c(brca=brca_freq
, luad=luad_freq
, lusc=lusc_freq
, stad = stad_freq
, coadread = coadread_freq
)
, colNum = 2 # number of columns in the plot
, cex.main = 1 # size of the plot title
, noPlot=TRUE
)$plottedTable %>% data.frame()
# name first column with frequency of patients with at least one alteration that makes the patients elibigle for treatment with a specific drug
names(drug_df)[1] <- "freq"
# generate plot
drug_df %>%
tibble::rownames_to_column("drug_name") %>%
dplyr::filter(!grepl("no_drug", drug_name)) %>%
ggplot(aes(x=reorder(drug_name, freq), y=freq*100)) +
geom_bar(stat="identity") +
coord_flip() +
labs(title="Max frequencies of patients elibigle for each drug treatment") +
ylab(label = "detected fraction indicated as the overall population percentage") +
xlab(label = "Drug name")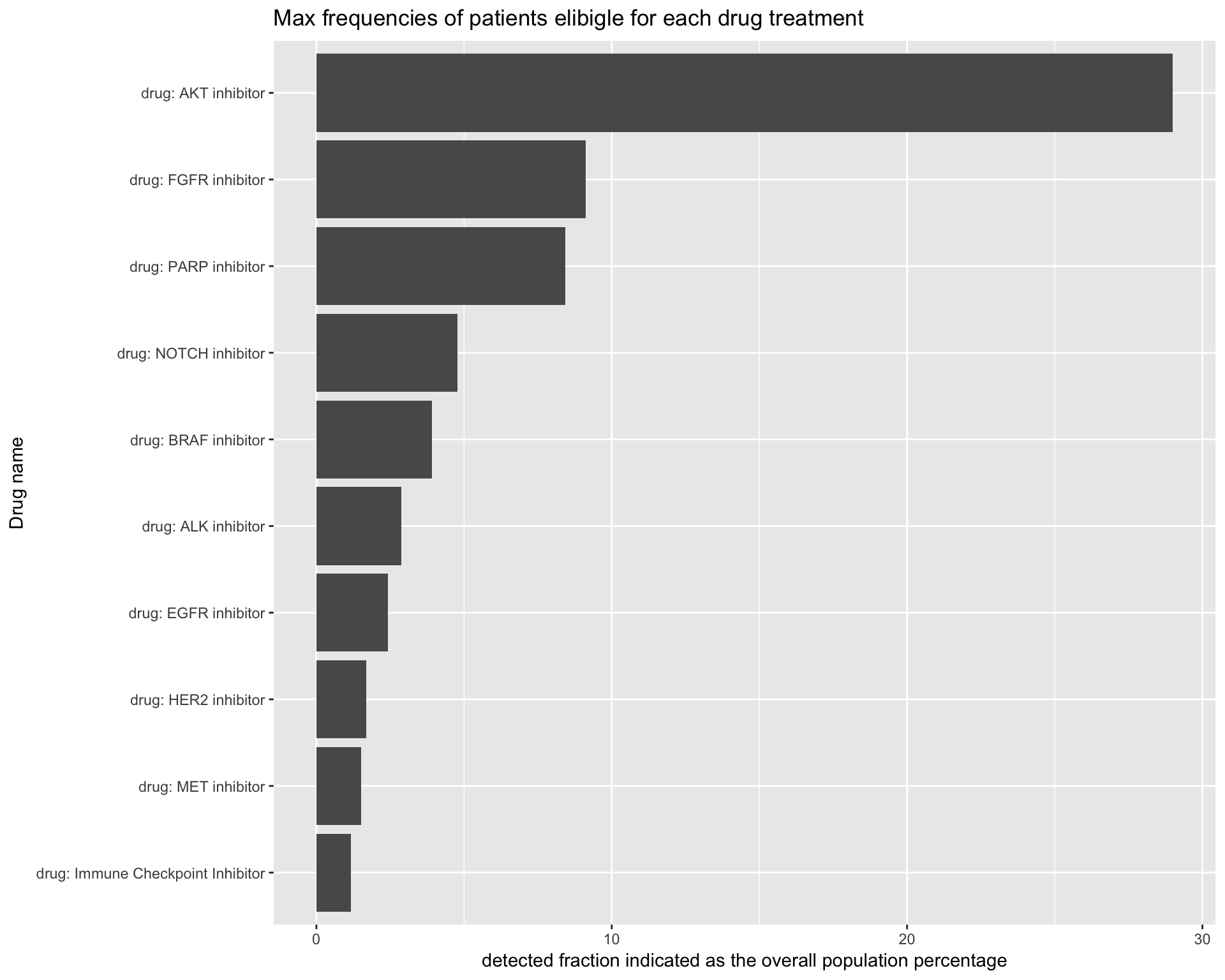
Generate the same plot this time running a weighted resampling simulation.
# Run simulation
# ------------------------------------------------------------------------------
N_SIMULATIONS = 200
simul <- lapply(1:N_SIMULATIONS , function(x) {
drug_df <- coveragePlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, grouping="drug"
# adjust population distribution by applying a weighted resampling
, tumor.weights = c(brca=ceiling(brca_tot/100)
, luad=ceiling(luad_tot/100)
, lusc=ceiling(lusc_tot/100)
, stad = ceiling(stad_tot/100)
, coadread = ceiling(coadread_tot/100)
)
, colNum = 2 # number of columns in the plot
, cex.main = 1 # size of the plot title
, noPlot=TRUE
, maxNumAlt = 1
)
return(drug_df$plottedTable/drug_df$Samples[1])
})
# Convert to dataframe
drug_vector <- unique(PTD_panel@arguments$panel$drug)
# Create a custom function to manage the problem with the function output CoveragaPlot not
# outputting the same number of ites in the simualation The function takes the labels, the
# vector and rematches, adding NA when a match is missing
value2slot <- function(value_vector, labels_vector){
# Cycle through the vector
temp_vector <- rep(0, times=length(labels_vector))
for (i in 1:length(labels_vector)){
# for each position in the vector fetch
value <- value_vector[i]
label <- rownames(value_vector)[i] %>% gsub("drug: ", "", .)
#get location index
index <- labels_vector %in% label
# qc
if(sum(index)>1) {stop("label mateched to more than one location")}
# replace value to that index position
temp_vector[which(index)] <- value
}
# add labels to the vector
names(temp_vector) <- labels_vector
return(temp_vector)
}
# test the function
#value2slot(simul[200][[1]], drug_vector)
# apply transformation to make it into a dataframe
simul_df <- purrr::map(simul, ~ value2slot(., drug_vector)) %>%
data.frame %>%
t()
# remove undesired rownames
row.names(simul_df) <- NULL
# GET STATS
# ------------------------------------------------------------------------------
# Calculate for each n° of alteration, the mean
detectionPower <- colMeans(simul_df)
# Calculate lower CI for resampling
leftCI <- apply(simul_df,2,function(x){left <- quantile(x, 0.025)})
# Calculate upper CI for resampling
rightCI <- apply(simul_df,2,function(x){right <- quantile(x, 0.975)})
# Preapre for column with # alterations
n_alterations <- 1:length(detectionPower)
# Put them all together in a data frame
dtpow <- data.frame(n_alterations, detectionPower, leftCI, rightCI) %>%
tibble::rownames_to_column("drug_name") %>%
dplyr::filter(!drug_name %in% "no_drug") # remove no_drug from the dataset
# Generate the plot
PTD_detection_image <- dtpow %>%
ggplot(aes(x=reorder(drug_name, detectionPower), y = detectionPower)) +
geom_bar(stat="identity" , position = position_dodge()) +
scale_y_continuous(limits = c(0,.5)) +
#scale_x_discrete(labels = dtpow[order(dtpow$detectionPower, decreasing = TRUE),"drug_name"]) +
#scale_x_continuous(breaks = n_alterations, trans = "reverse") +
geom_errorbar(aes(ymax=rightCI
, ymin=leftCI)
, position=position_dodge(0.9)
, size=0.2
) +
ggtitle("Max frequencies of patients elibigle for each drug treatment") +
ylab(label = "detected fraction indicated as the overall population percentage") +
xlab(label = "Drug name") +
annotate("text"
, x=reorder(dtpow$drug_name, dtpow$detectionPower)
, y=dtpow$detectionPower + 0.15
, label= sapply(dtpow$detectionPower*100
, function(x) paste(c(round(x, digits = 2), "%")
, collapse = " ")
)
) +
coord_flip()
# Show image
PTD_detection_image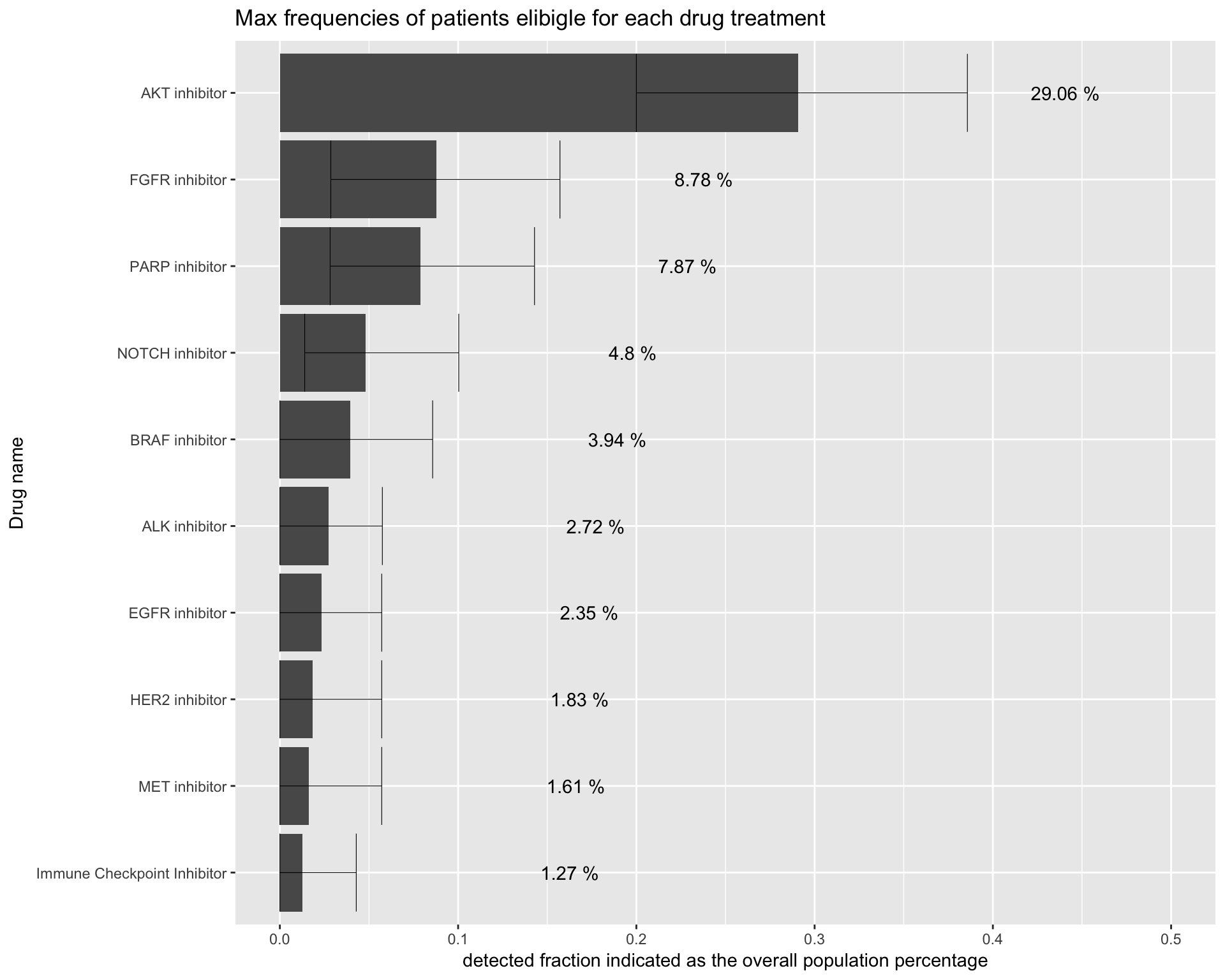
Panel performance evaluation
The design phase of a panel requires the user to make the important decision about what genes to include. PTD provides a suite of tools envisioned to aid the user during the decision process and evaluate the performance of the panel.
Rank genes in the design in terms of genomic space/detected fraction
The following plot was studied to investigate the relationship between the “cost” of adding new genes to the panel (as a function of genomic space to be included among the genomic regions to be targeted) and the detected fraction in terms of the mean number of alterations found in the samples (cancer population), for that specific gene in a specific set of tumor types.
In order to optimize a panel design, we might be interested to know:
- What genes are most altered in the tumor types of interest;
- What genes are “cheaper” to be sequenced (in terms of genomic spaces, or also size of the targeted region);
- What genes have the highest number of (alteration frequency) / (genomic space).
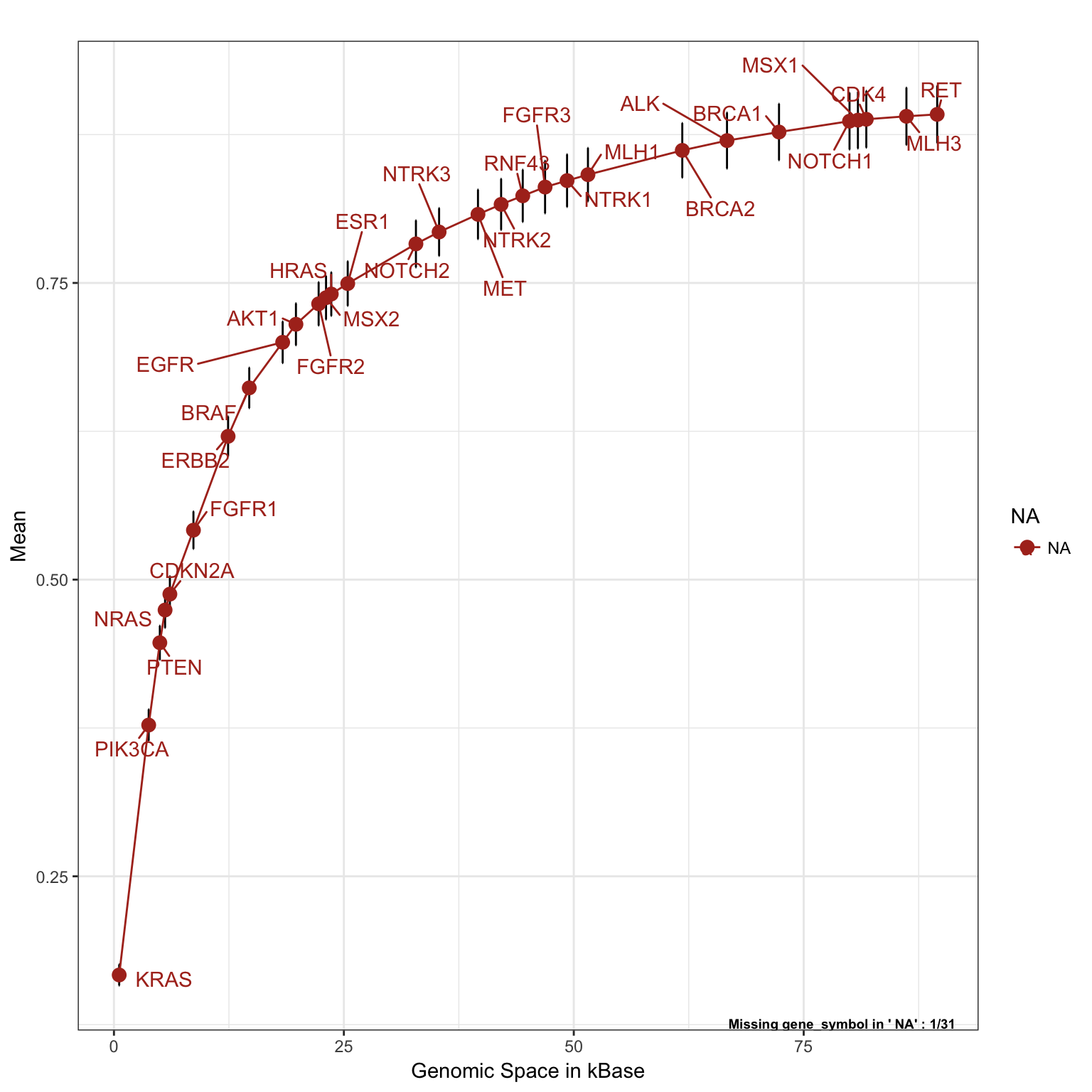
All tumors together
The following saturation plot shows the overall performance of the panel in a population that includes all tumor types of interest (balanced by tumor frequency in the population of reference). Genes can be ranked based on the ratio (alteration frequency) / (genomic space). Genes with highest mean number of alteration per sample and smallest size are listed first. The following genes in the plot are added one by one incrementally. This means that on the y-axis, every time we add a new gene, we are adding only the incremental contribution of alteration for that specific gene. This was done to prevent from counting twice (or more than once), patients with genes that were already found altered.
saturationPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, adding="gene_symbol"
# adjust population distribution by applying a weighted resampling
, tumor.weights=c(brca=brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, adding.order = "rate"
, legend = "out"
)
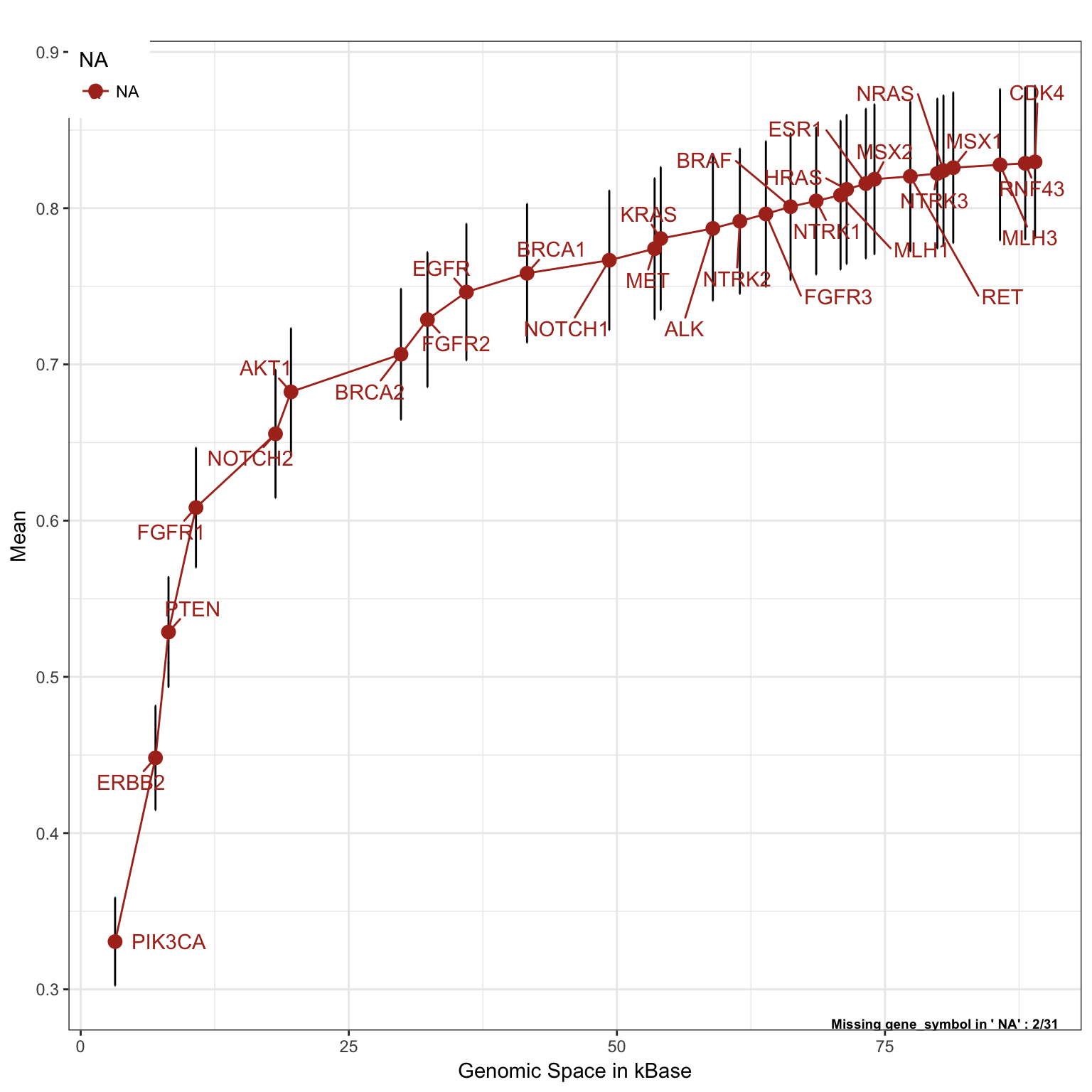
Each single cancer type will have different gene alteration frequencies, and therefore the order of the genes can change accordingly. In the following set of plots we will change the gene adding order, using asbolute ranking. This parameters, will not add genes based on their optimal ratio, but will priorities genes with the absolute highest number of alterations found in each single tumor group of interest
Breast Cancer
saturationPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, adding="gene_symbol"
, tumor_type = "brca"
, adding.order = "absolute"
)
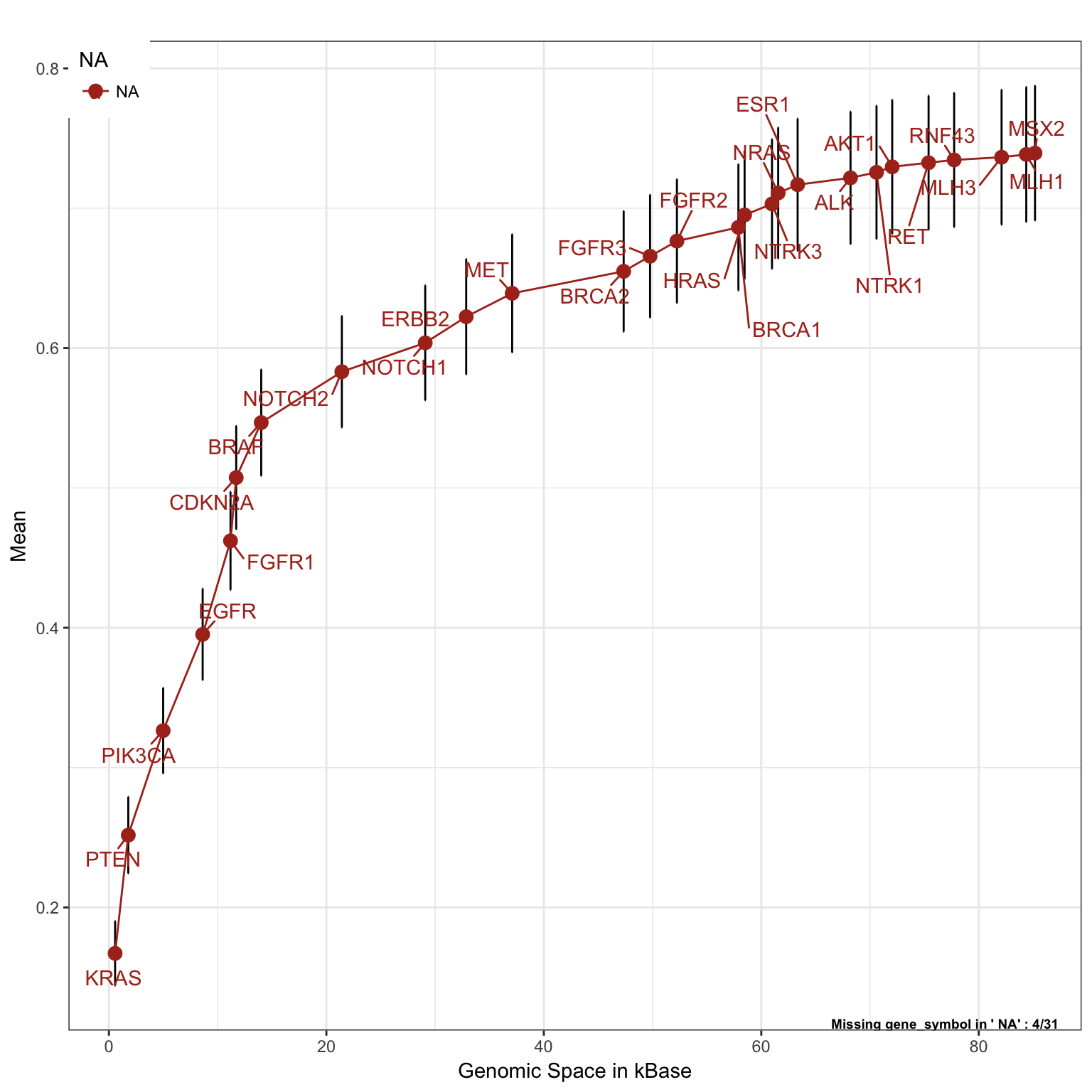
Lung Cancer, mutations and copy number alterations
saturationPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, adding="gene_symbol"
, tumor_type = c("luad", "lusc")
, adding.order = "absolute"
)
Lung Cancer, only fusion alterations
saturationPlot(PTD_panel
, alterationType=c("fusions")
, adding="gene_symbol"
, tumor_type = c("luad", "lusc")
, adding.order = "absolute"
)## Warning in dataExtractor(object = object, alterationType =
## alterationType, : The following tumor types have no alteration to display:
## lusc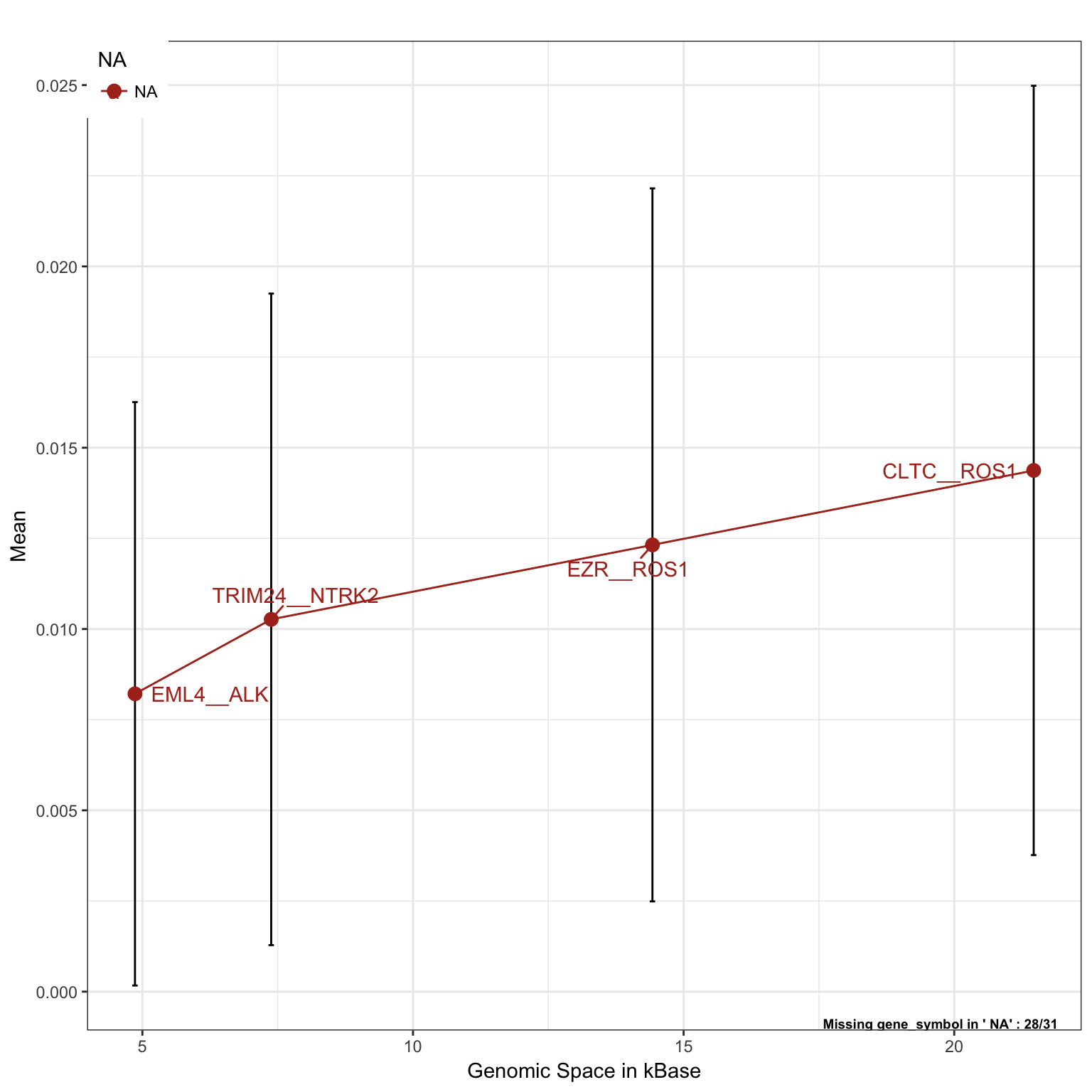
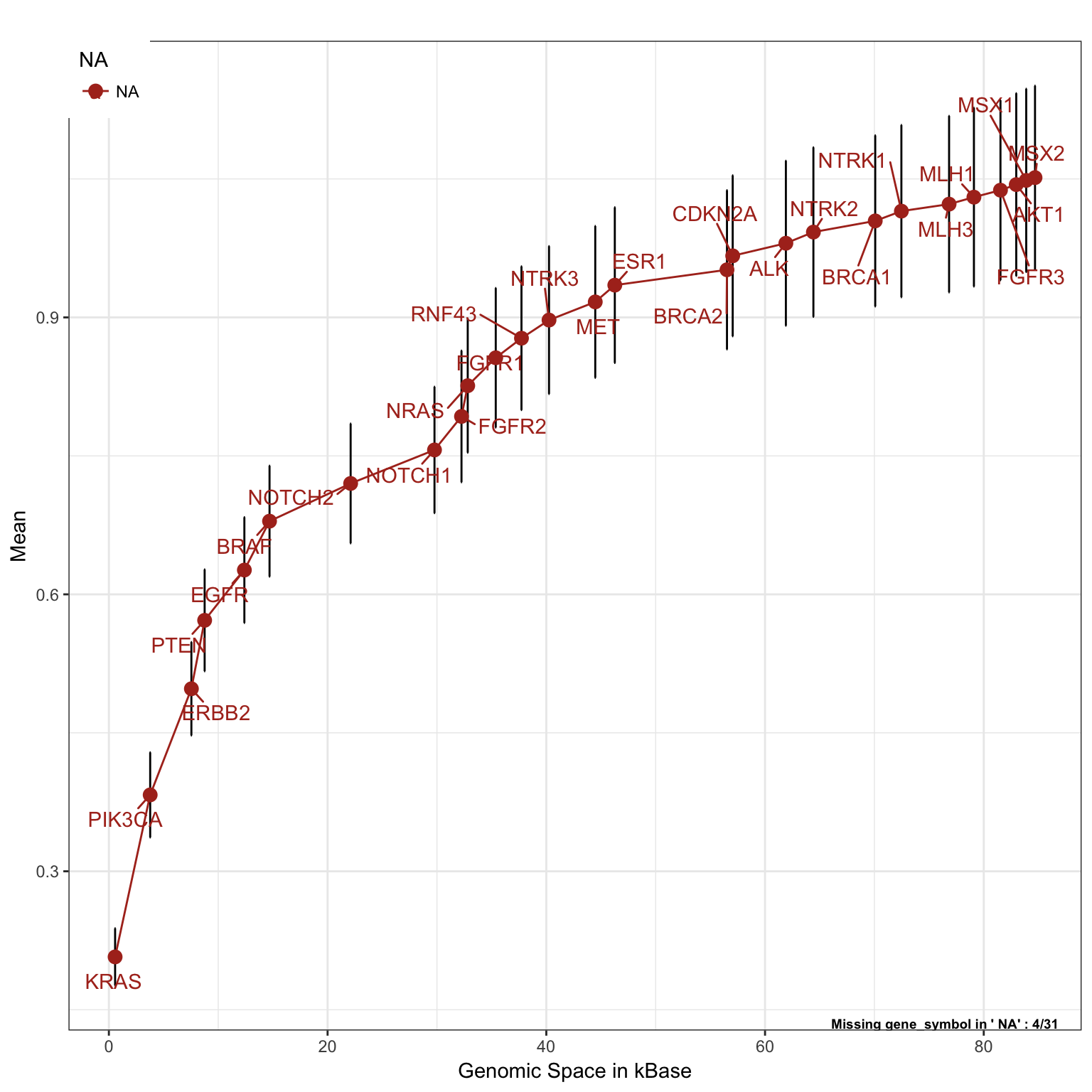
Gastric Cancer
saturationPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, adding="gene_symbol"
, tumor_type = c("stad", "coadread")
, adding.order = "absolute"
)
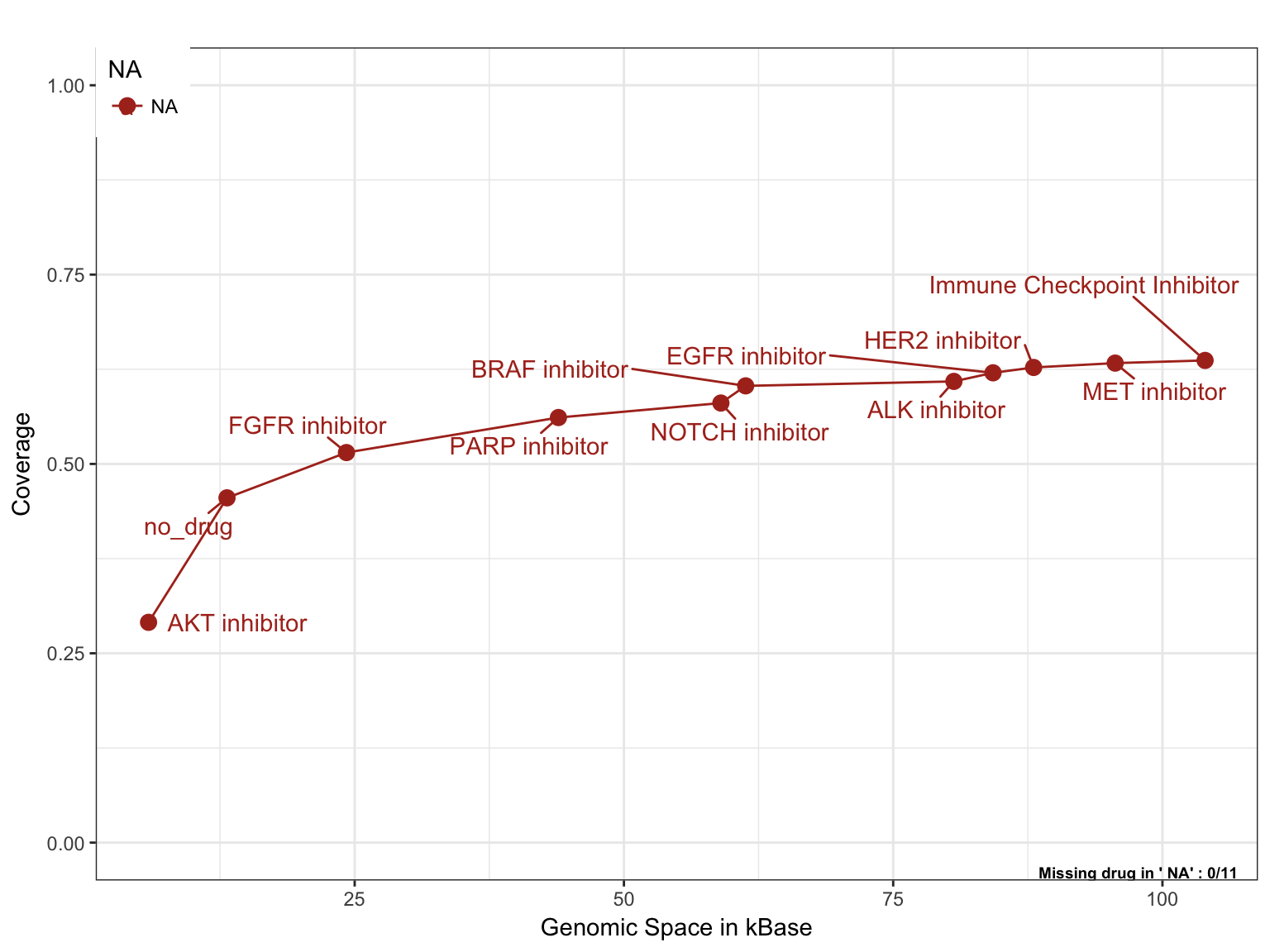
Rank drugs in the design in terms of genomic space/patient allocation
Similarly to the previous set of plots, we can investigate the cost of adding a new drug in the study in terms of extra genomic space to be targeted by the panel with respect to the alteration frequency of population that can be captured.
saturationPlot(PTD_panel
, alterationType=c("mutations", "copynumber")
, adding="drug"
, y_measure="absolute"
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
)
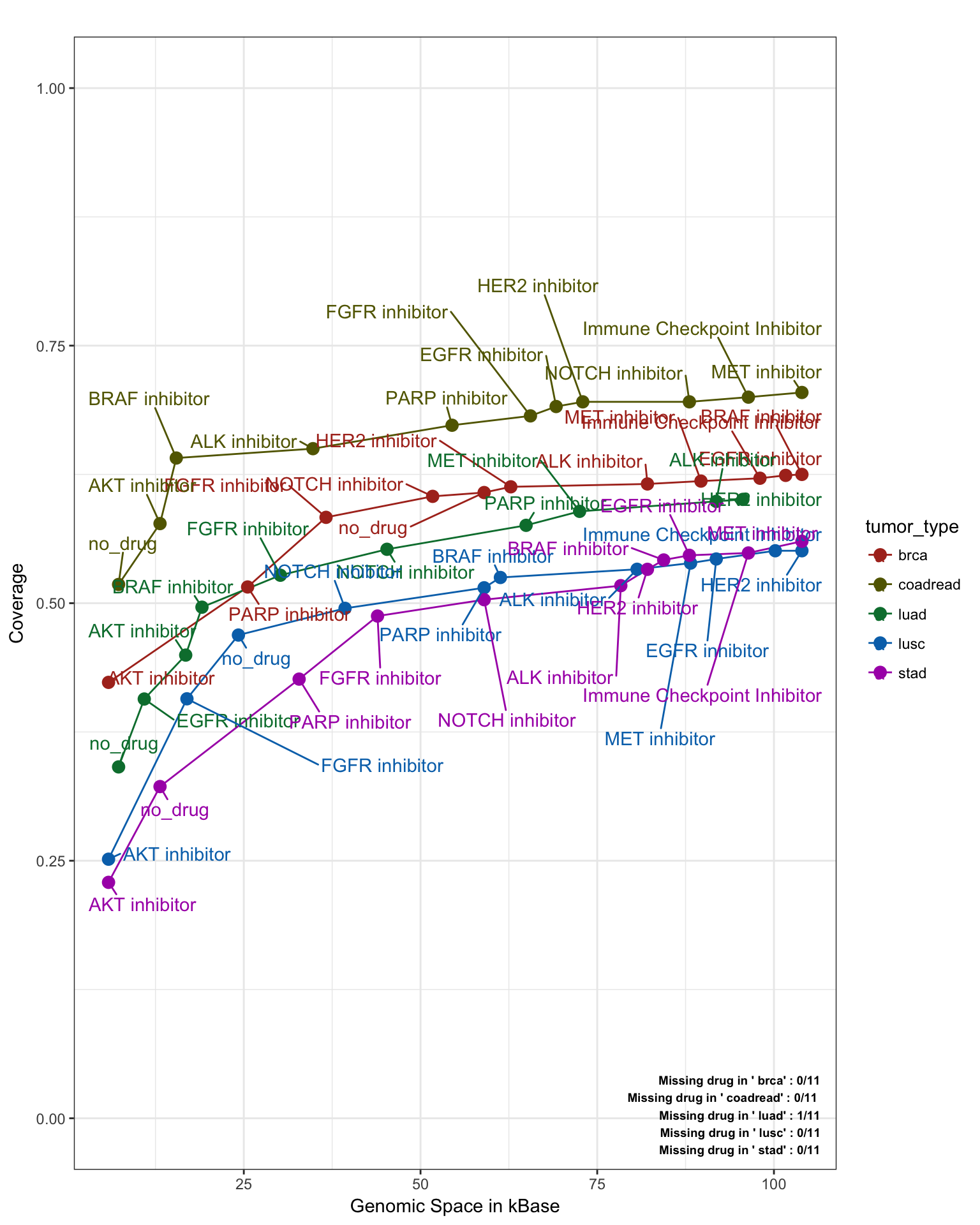
Similarly, we can separate the saturation line by tumor_types. (Note: In the following plot we do not need to apply the tumor.wight option, as we are grouping by tumor_types, Note2: no_drug indicates frequency associated with driver genes which are therefore not associated to any drug treatment in this specific design).
saturationPlot(PTD_panel
, alterationType=c("mutations", "copynumber")
, grouping="tumor_type"
, adding="drug"
, y_measure="absolute"
, legend = "out"
)
To improve the readability of the plot, we can look at each single tumor type individually.
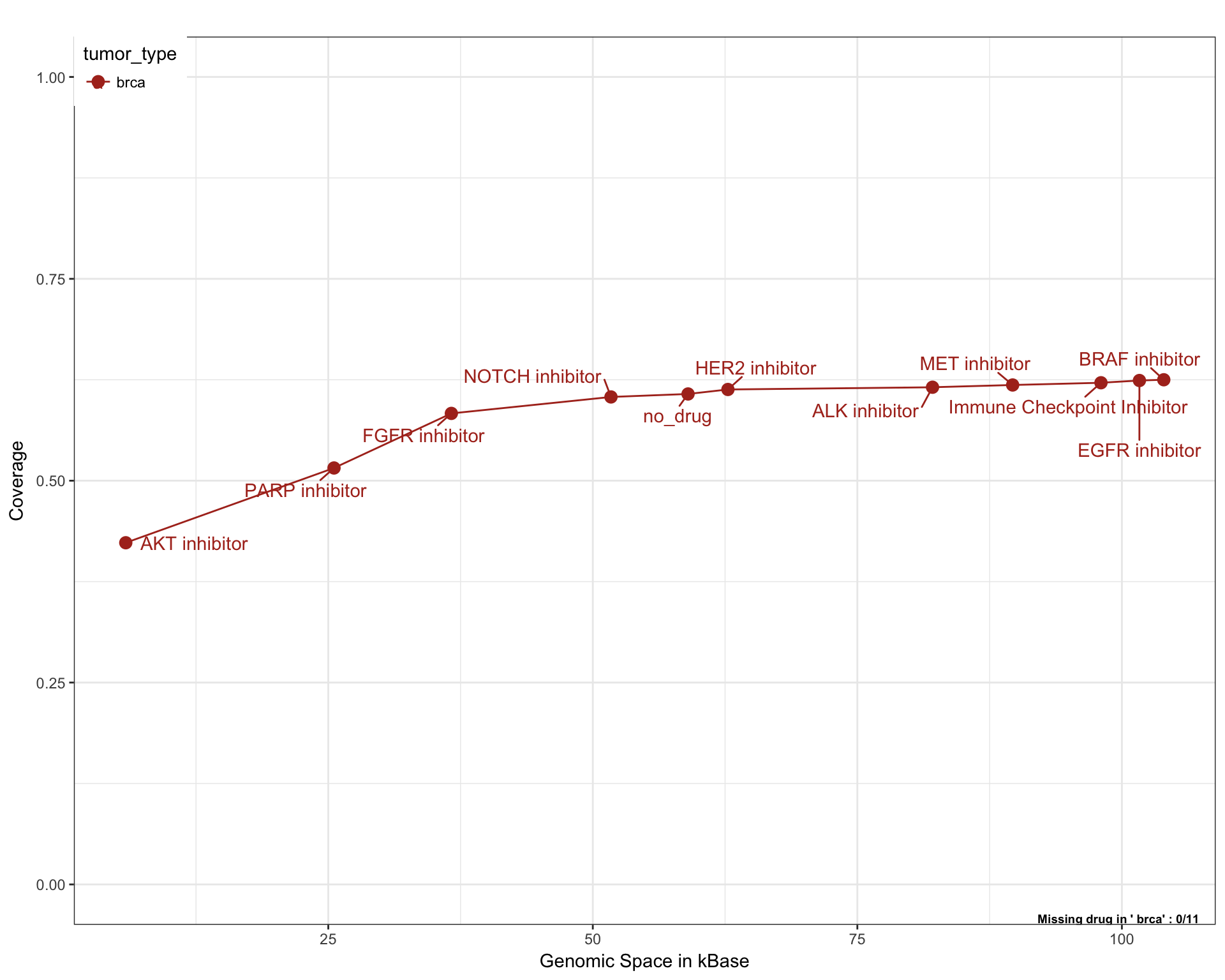
Breast Cancer
# Generate plots for each tumor types
saturationPlot(PTD_panel
, alterationType=c("mutations", "copynumber")
, grouping="tumor_type"
, adding="drug"
, y_measure="absolute"
, tumor_type = "brca"
) 
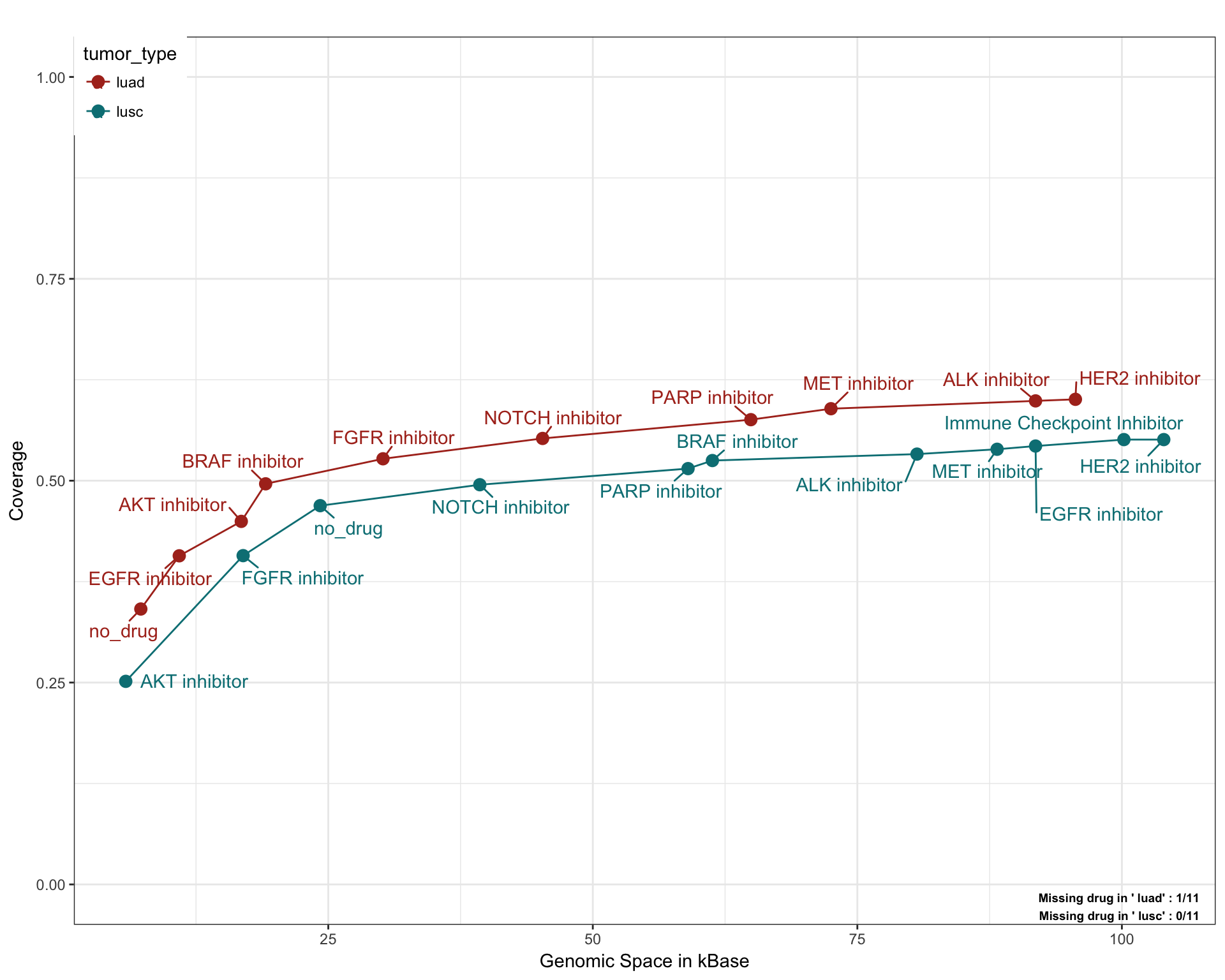
Lung Cancer
saturationPlot(PTD_panel
, alterationType=c("mutations", "copynumber")
, grouping="tumor_type"
, adding="drug"
, y_measure="absolute"
, tumor_type = c("luad", "lusc")
)
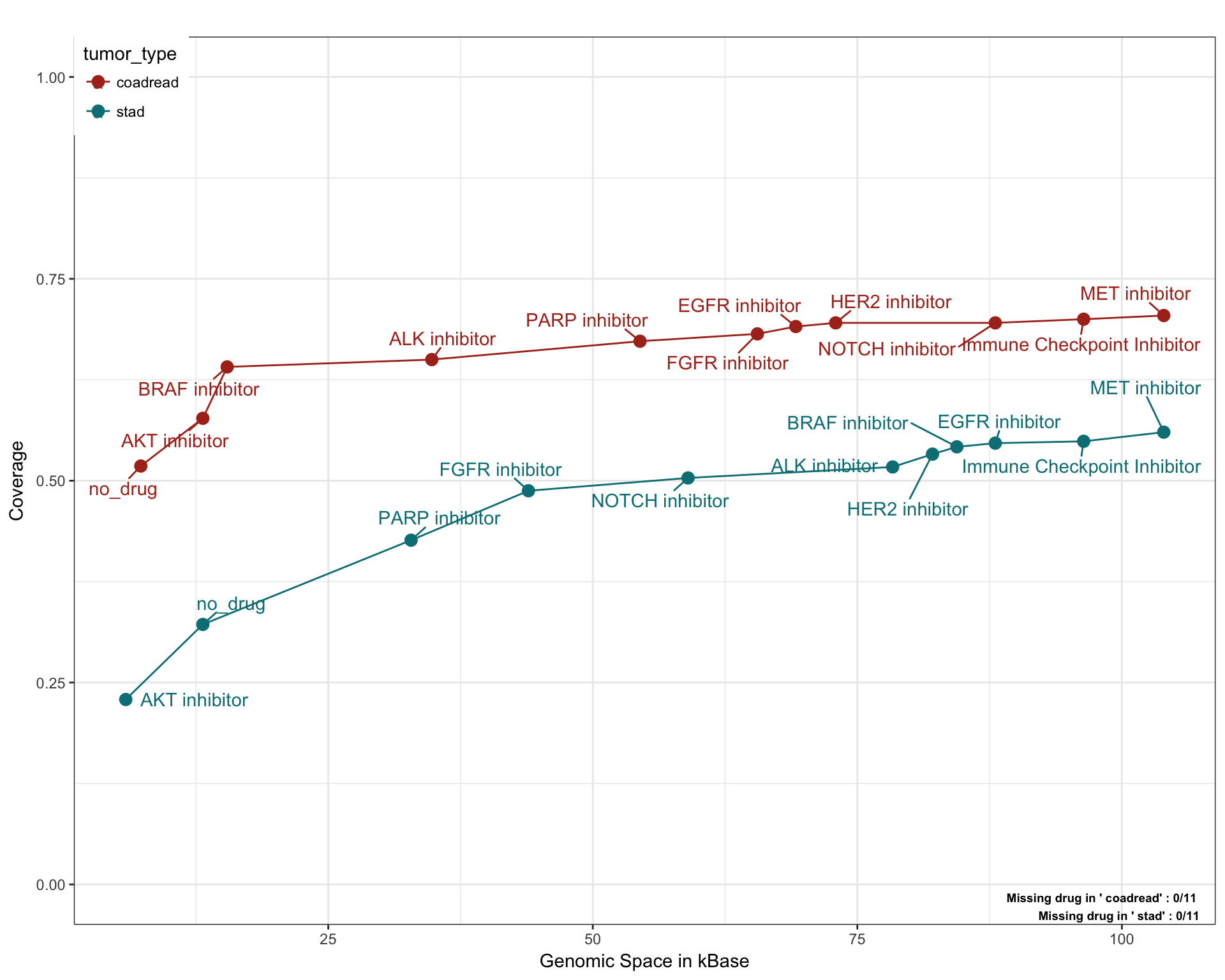
Gastric Cancer
saturationPlot(PTD_panel
, alterationType=c("mutations", "copynumber")
, grouping="tumor_type"
, adding="drug"
, y_measure="absolute"
, tumor_type = c("coadread", "stad")
) 
Panel detected fraction of each alteration type in the overall population
SNV and indels detection are today part of standard analysis for NGS application.However, CNA (Copy number alteration) detection, or fusion analysis are still not standardized analysis and they do not represent an easy implementation. In the following plot we will investigate the contribution of the detected fraction of each alteration type in case. This will help us quantify, in case we decide to opt out the detection of some of the alteration type, the influence of each single alteration type in the detected fraction.
saturationPlot(PTD_panel
, alterationType=c("mutations" , "copynumber", "fusions")
, adding="gene_symbol"
, tumor.weights=c(brca=brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
,grouping="alteration_id"
)## Warning in dataExtractor(object = object, alterationType =
## alterationType, : The following tumor types have no alteration to display:
## stad, coadread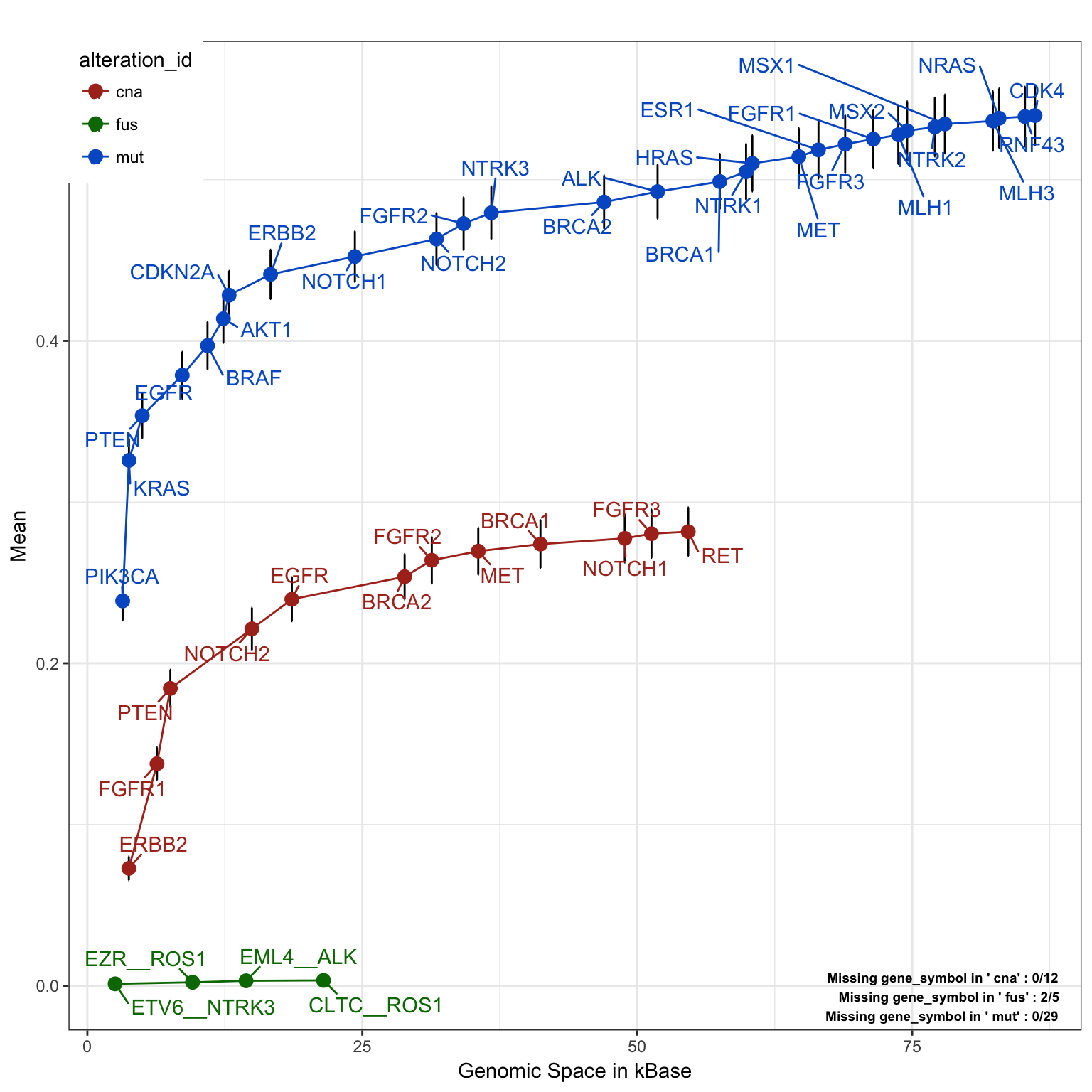
Drug targeting frequency plot
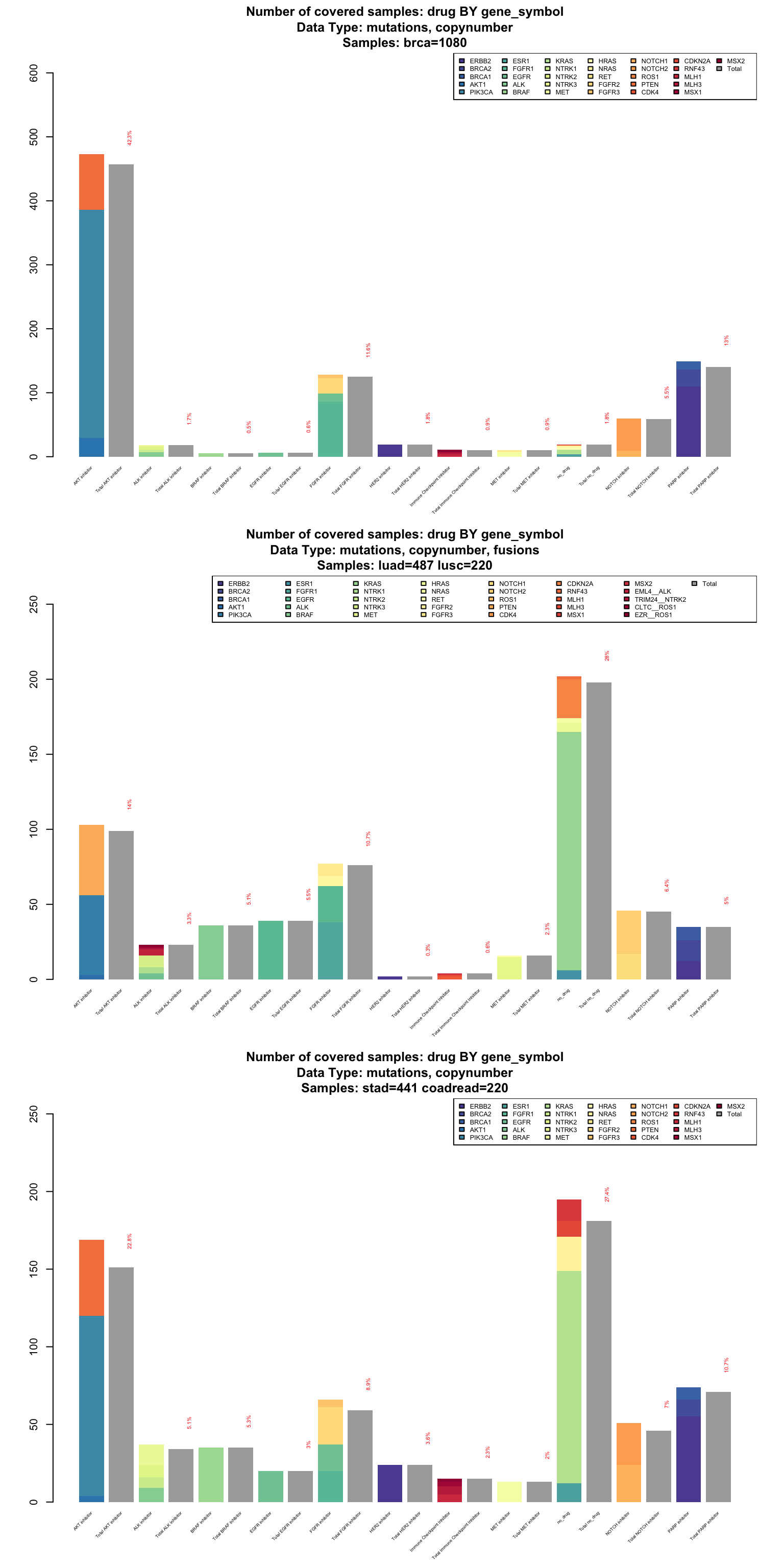
In case some of the drugs are multitarget (in this panel design, we are using drug families), it might be interesting to investigate what are the most targeted genes in our population of reference. We can visualize this information as an independent stack plot for each tumor type.
par(mfrow=c(3,1))
coverageStackPlot(PTD_panel
, alterationType=c("mutations", "copynumber")
, var="drug"
, grouping="gene_symbol"
, tumor_type="brca"
)
coverageStackPlot(PTD_panel
, alterationType=c("mutations" , "copynumber" , "fusions")
, var="drug"
, grouping="gene_symbol"
, tumor_type=c("luad", "lusc")
)
coverageStackPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, var="drug"
, grouping="gene_symbol"
, tumor_type=c("stad", "coadread")
)
# reset plot settings
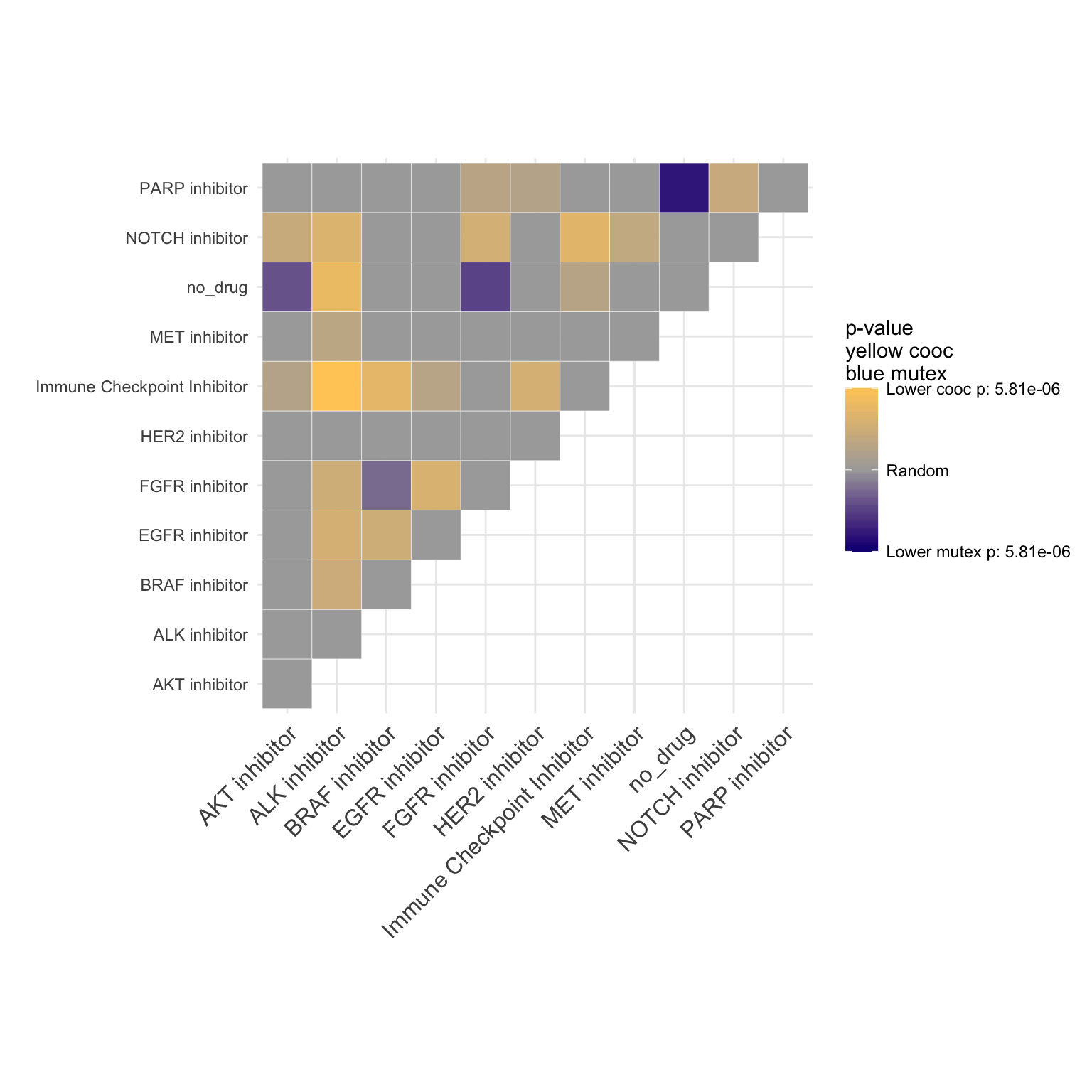
par(mfrow=c(1,1))We can also visualize co-occurrence and mutual exclusivity of the drugs in different tumor types.
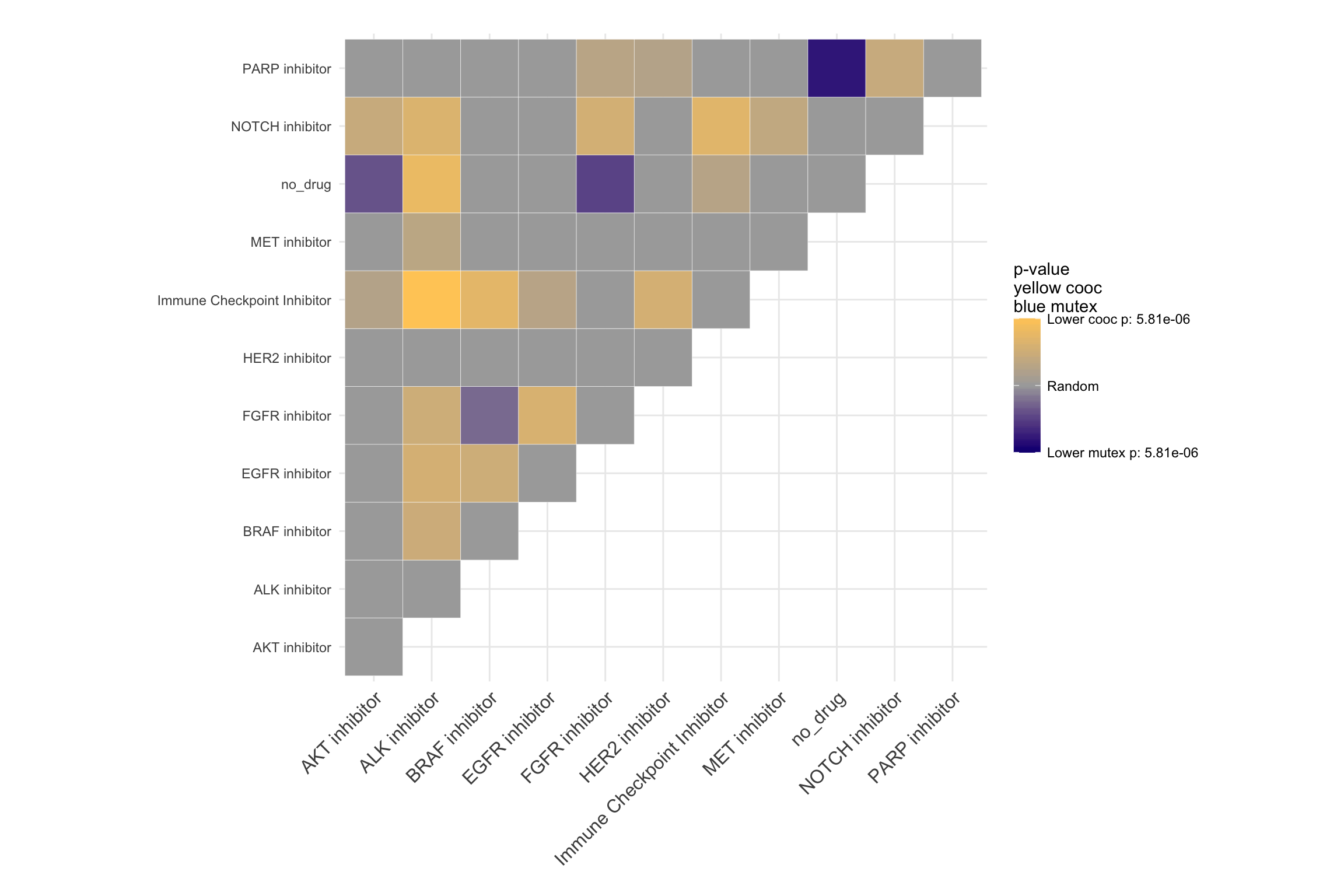
Overall Co-occurance
coocMutexPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
, var="drug"
# , grouping="group"
, tumor.freqs = c(brca=brca_freq
, luad=luad_freq
, lusc=lusc_freq
, stad = stad_freq
, coadread = coadread_freq
)
)
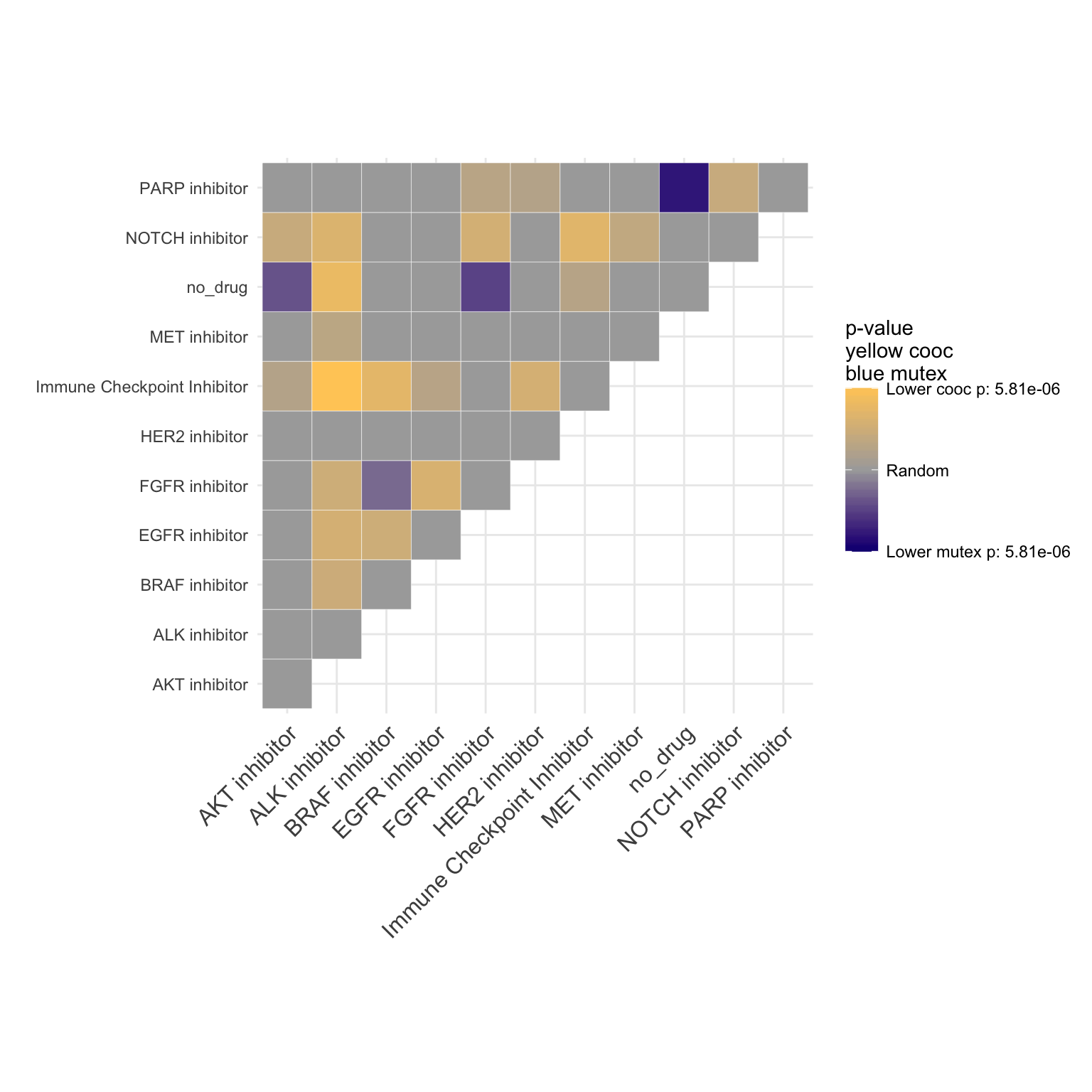
Breast cancer co-occurence plot
coocMutexPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
#, grouping="alteration_id"
, var="drug"
, tumor_types= "brca"
)
Lung cancer co-occurence plot
coocMutexPlot(PTD_panel
, alterationType=c("mutations" , "copynumber", "fusions" )
#, grouping="alteration_id"
, var="drug"
, tumor_types= c("luad", "lusc")
)## Warning in dataExtractor(object = object, alterationType =
## alterationType, : The following tumor types have no alteration to display:
## stad, coadread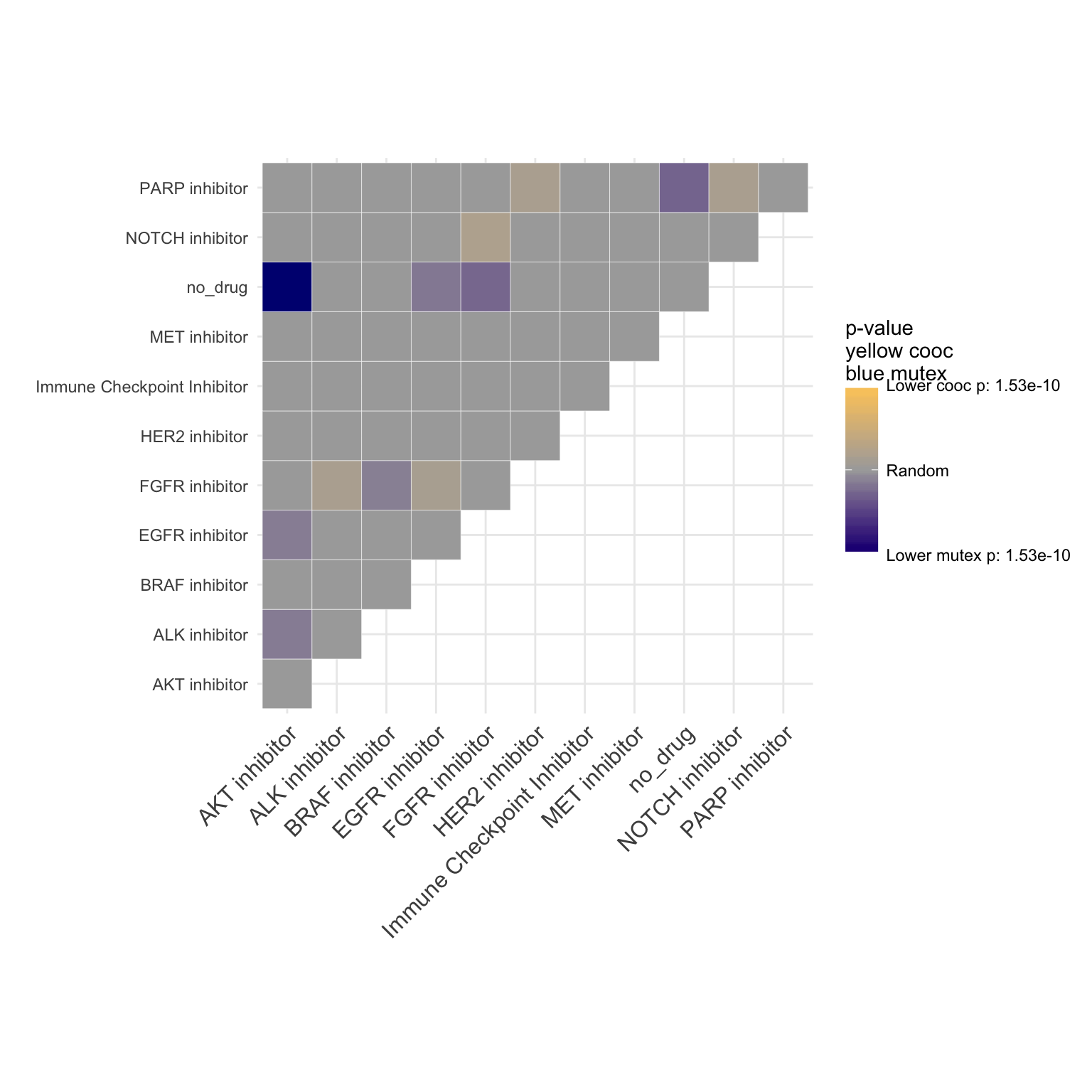
Gastric cancer co-occurence plot
coocMutexPlot(PTD_panel
, alterationType=c("mutations" , "copynumber")
#, grouping="alteration_id"
, var="drug"
, tumor_types= c("egc", "stad", "coadread")
)
How many patients are eligible to more than one treatment?
Some patients are eligible to more than one therapy group. We will take advantage of this information in a later stage of the analysis as it will allows us to to optimize the patients allocation and improve the changes of the clinical trial of reaching statistical power.
# Prepare dataframe on which to run the analysis
# ------------------------------------------------------------------------------
# Extract data
data <- dataExtractor(PTD_panel , alterationType = c("mutations" , "copynumber" , "fusions"))## Warning in dataExtractor(PTD_panel, alterationType = c("mutations",
## "copynumber", : The following tumor types have no alteration to display:
## stad, coadread# Extract case_id and drug columns
dataDrug <- unique(data$data[ , c("case_id" , "drug")])
# calculate number of drug per patient, taking into account ALL samples
drugsPerPatient <- table( factor(dataDrug$case_id , levels = data$Samples$all_tumors) )
# Calculate the frequenecy of patients eligible to at least X number od drugs
alPatDrug <- sapply(1:max(drugsPerPatient), function(x){
sum(drugsPerPatient >= x) / length(drugsPerPatient)
}
) %>%
data.frame(drugs=.)
# Plot
alPatDrug %>%
ggplot(aes(x=1:length(drugs), y=drugs)) +
geom_bar(stat="identity") +
labs(title="Patients eligible to AT LEAST 1, 2, 3 or 4 ... drugs") +
ylab(label = "Eligibility frequency") +
xlab(label = "Number of drugs the patient is eligible for") +
theme(legend.position="none") +
geom_text(aes(label=stringr::str_c(round(drugs, digits=4)*100, " %"), y=drugs+0.05), position = position_dodge(width=0.9))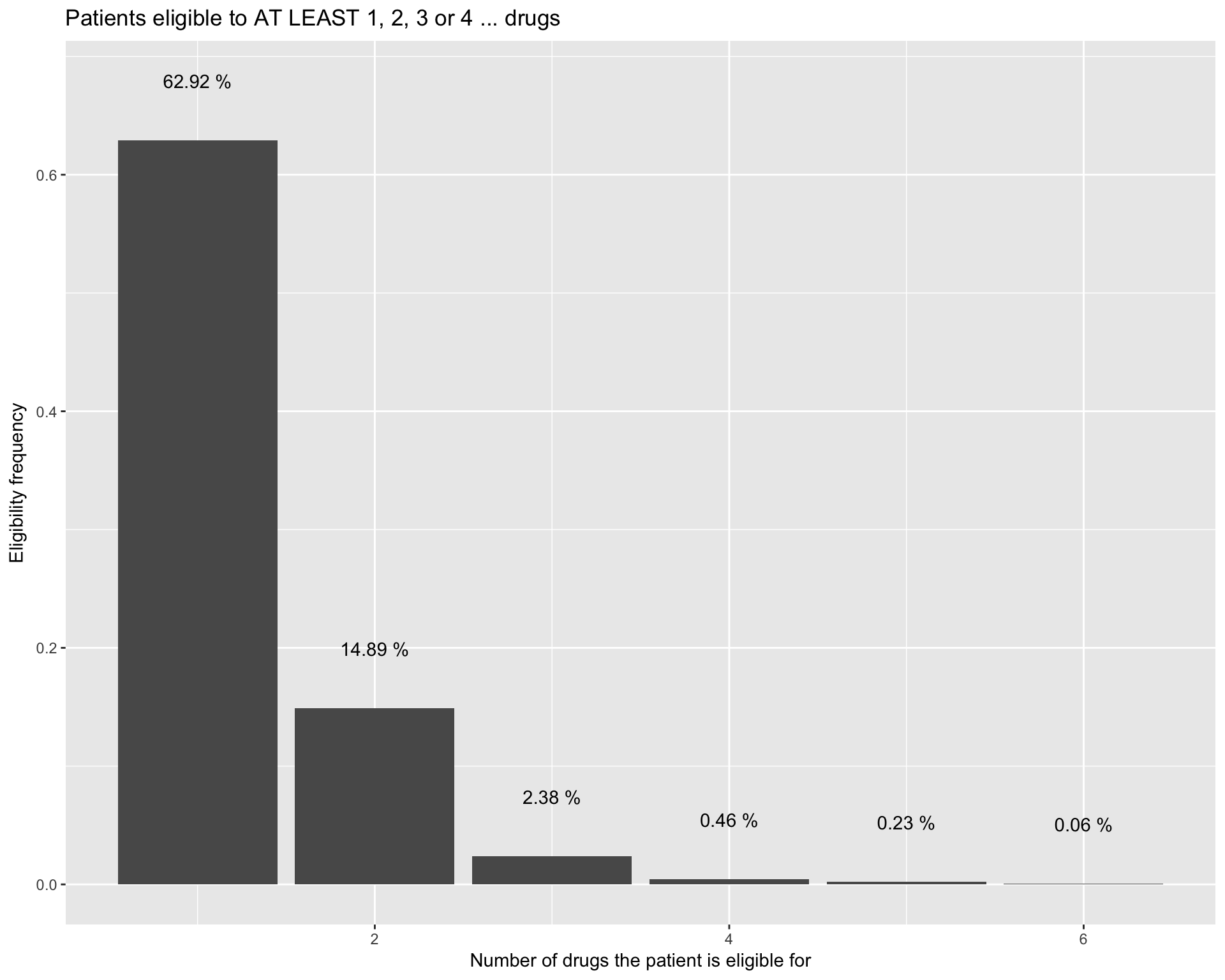
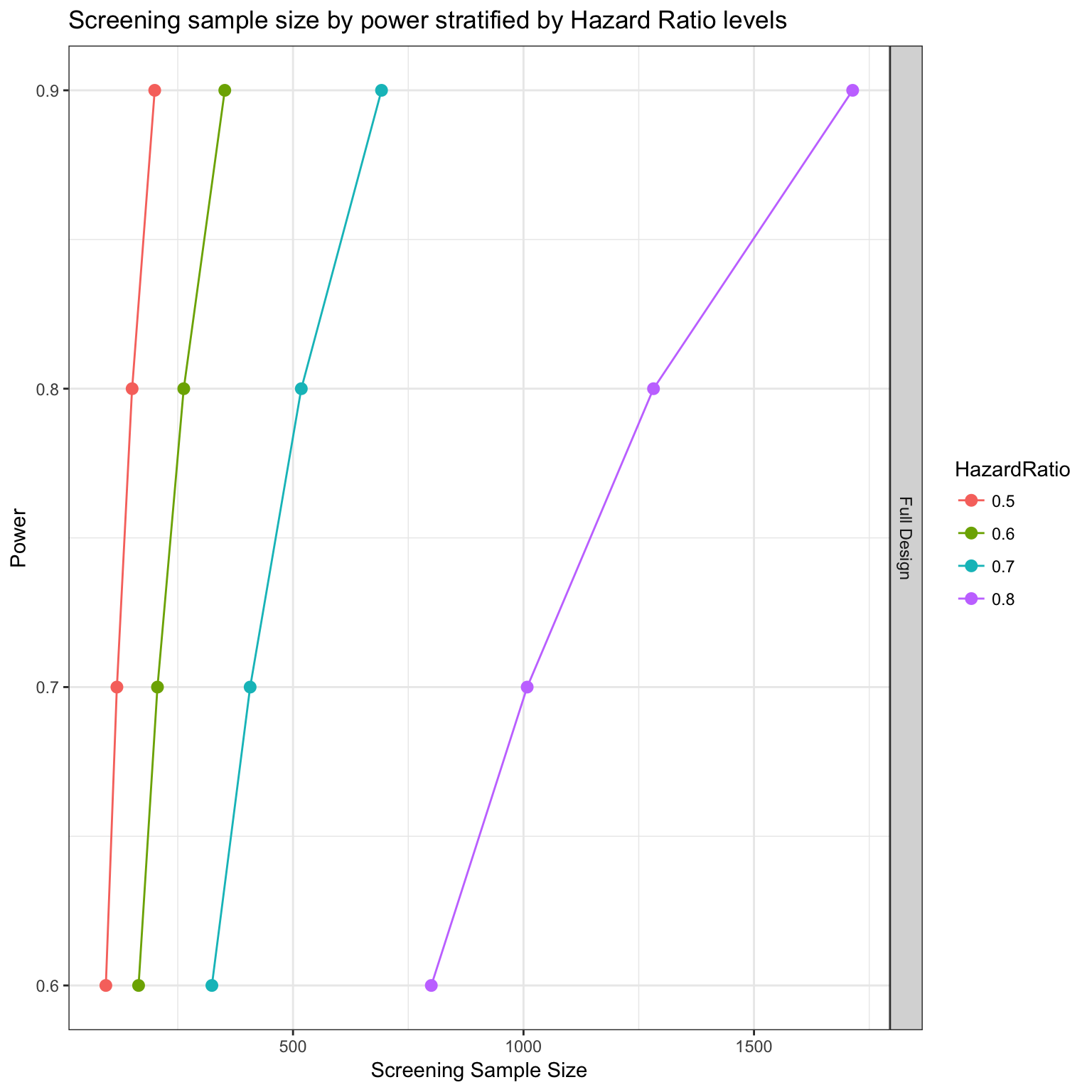
Power analysis
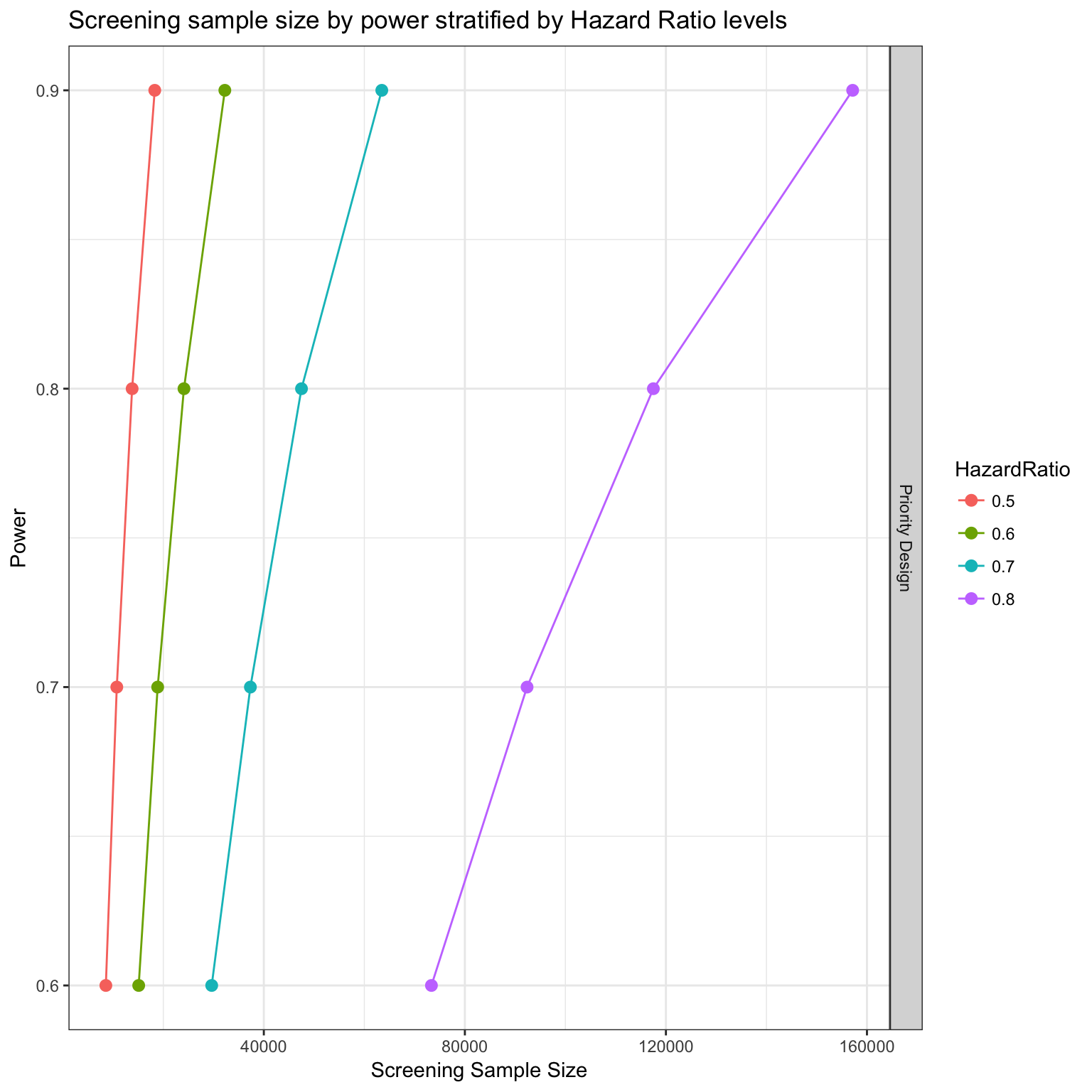
We can now simulate a clinical trial based on the drug-gene targeting design, and estimate the number of patients that needs to be recruited.
- We will look at 4 power levels: 0.6, 0.7, 0.8, 0.9
- and we will consider different Hazard ratios
Overall power analysis for the full study
# Generate plot
survPowerSampleSize(PTD_panel
, alterationType = c("mutations" , "copynumber")
, HR = c(0.5, 0.6, 0.7, 0.8)
, power = seq(0.6 , 0.9 , 0.1)
, alpha = 0.05
, case.fraction = 0.5
, tumor.weights = c(brca=brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
)
Preview the table with the data from the previous plot.
# Generate Table
survPowerSampleSize(PTD_panel
, HR = c(0.5, 0.6, 0.7, 0.8)
, power = seq(0.6 , 0.9 , 0.1)
, alpha = 0.05
, case.fraction = 0.5
, tumor.weights = c(brca=brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot =TRUE
) %>% kable()| Var | ScreeningSampleSize | EligibleSampleSize | Beta | Power | HazardRatio |
|---|---|---|---|---|---|
| Full Design | 94 | 59 | 0.4 | 0.6 | 0.5 |
| Full Design | 118 | 74 | 0.3 | 0.7 | 0.5 |
| Full Design | 151 | 95 | 0.2 | 0.8 | 0.5 |
| Full Design | 200 | 126 | 0.1 | 0.9 | 0.5 |
| Full Design | 165 | 104 | 0.4 | 0.6 | 0.6 |
| Full Design | 207 | 130 | 0.3 | 0.7 | 0.6 |
| Full Design | 264 | 166 | 0.2 | 0.8 | 0.6 |
| Full Design | 352 | 222 | 0.1 | 0.9 | 0.6 |
| Full Design | 324 | 204 | 0.4 | 0.6 | 0.7 |
| Full Design | 408 | 257 | 0.3 | 0.7 | 0.7 |
| Full Design | 519 | 327 | 0.2 | 0.8 | 0.7 |
| Full Design | 693 | 437 | 0.1 | 0.9 | 0.7 |
| Full Design | 801 | 505 | 0.4 | 0.6 | 0.8 |
| Full Design | 1009 | 636 | 0.3 | 0.7 | 0.8 |
| Full Design | 1283 | 809 | 0.2 | 0.8 | 0.8 |
| Full Design | 1716 | 1082 | 0.1 | 0.9 | 0.8 |
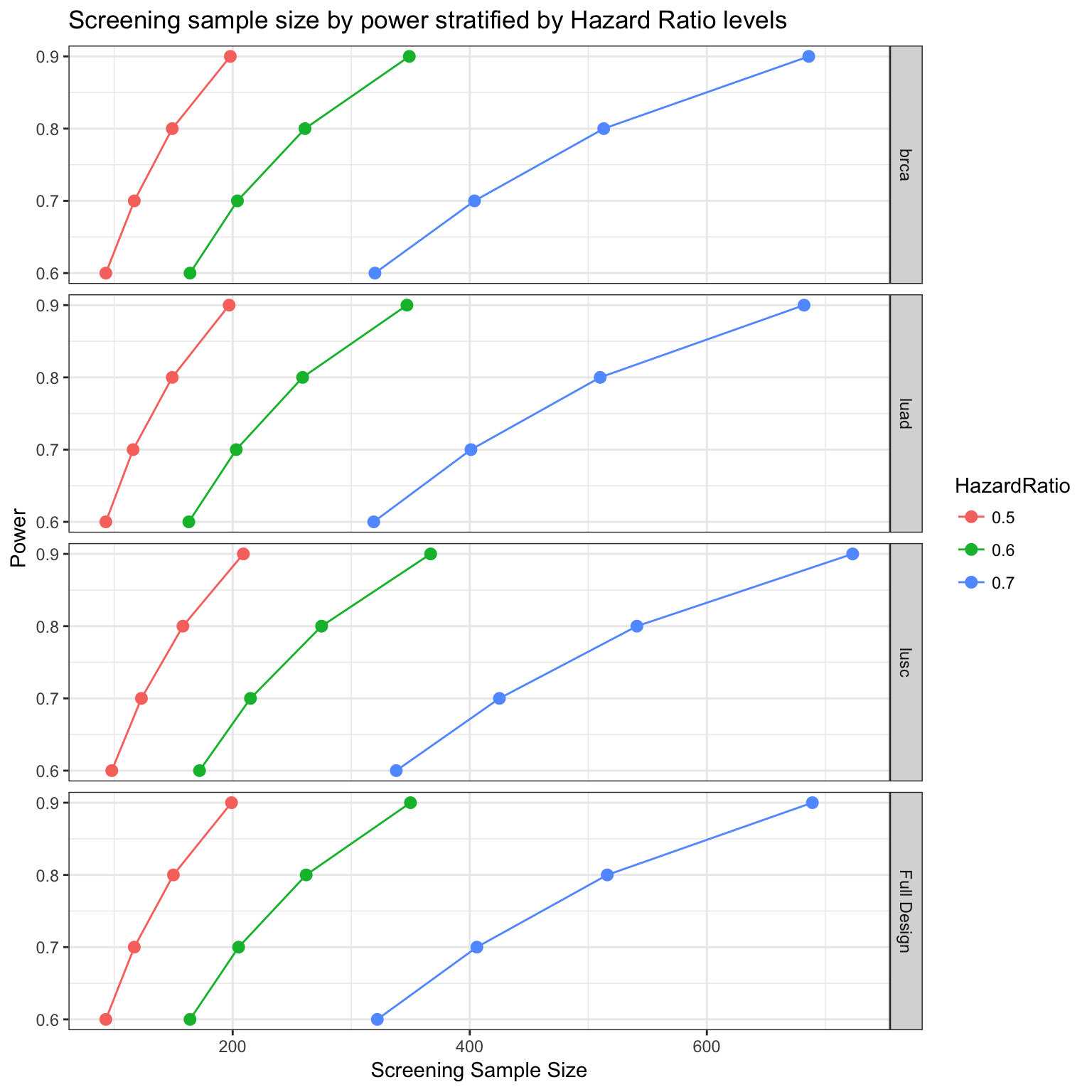
Power analysis per group treatment
The power analysis can also be performed grouping by tumor types.
survPowerSampleSize(PTD_panel
,var = "tumor_type"
, HR = c(0.5, 0.6, 0.7)
, power = seq(0.6 , 0.9 , 0.1)
, alpha = 0.05
, case.fraction = 0.5
, tumor.weights = c(brca=brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
)
PATIENT ALLOCATION OPTIMIZATION
In this section we will investigate how the patients could be allocated to the treatment groups. It is particularly interesting to notice that some patients are eligible to more than one therapy group, allowing to run optimization algorithms in order to better balance the patients allocation distribution in the different treatment arms reducing the number samples to screen.
Number of patients required for the overall study to reach the required power (using PFS)
In this simulation we are using Progression Free Survival as the primary endpoint.
drugs <- c("HER2 inhibitor"
, "PARP inhibitor"
, "AKT inhibitor"
, "EGFR inhibitor"
, "FGFR inhibitor"
, "ALK inhibitor"
, "BRAF inhibitor"
, "MET inhibitor"
, "NOTCH inhibitor"
, "Immune Checkpoint Inhibitor")
# Show plot
survPowerSampleSize(PTD_panel
, HR = c(0.5, 0.6, 0.7, 0.8)
, power = seq(0.6 , 0.9 , 0.1)
, alpha = 0.05
, case.fraction = 0.5
, priority.trial = drugs
, priority.trial.order="optimal"
, var = "drug"
, tumor.weights = c(brca=brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
)
Show in a table the Power 0.8 and HR = 0.6
# Show it in a table
survPowerSampleSize(PTD_panel
, HR = 0.6
, power = 0.8
, alpha = 0.05
, case.fraction = 0.5
, priority.trial = drugs
, priority.trial.order = "optimal"
, var = "drug"
, noPlot = TRUE
, tumor.weights = c(brca = brca_tot
, luad = luad_tot
, lusc = lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
)$`HR:0.6 | HR0:1 | Power:0.8`$Summary %>%
data.frame() %>%
tibble::rownames_to_column("criteria") %>%
tidyr::gather(drug, patients, 2:ncol(.)) %>%
tidyr::spread(criteria, patients) %>%
dplyr::select(drug, Screened, Eligible, Not.Eligible) %>%
knitr::kable()## Warning in dataExtractor(object = object, alterationType =
## alterationType, : No data for expression. They will be removed from
## alterationType## Warning in dataExtractor(object = object, alterationType =
## alterationType, : The following tumor types have no alteration to display:
## stad, coadread##
## Minimum Eligible Sample Size to reach 80% of power with an HR equal to 0.6 and a HR0 equal to 1 for each drug is equal to: 166| drug | Screened | Eligible | Not.Eligible |
|---|---|---|---|
| AKT.inhibitor | 0 | 5120 | 0 |
| ALK.inhibitor | 0 | 404 | 0 |
| BRAF.inhibitor | 0 | 431 | 0 |
| EGFR.inhibitor | 0 | 467 | 0 |
| FGFR.inhibitor | 0 | 1782 | 0 |
| HER2.inhibitor | 0 | 297 | 0 |
| Immune.Checkpoint.Inhibitor | 21504 | 166 | 9606 |
| MET.inhibitor | 0 | 256 | 0 |
| NOTCH.inhibitor | 0 | 1216 | 0 |
| PARP.inhibitor | 0 | 1764 | 0 |
| Total | 21504 | 11899 | 9606 |
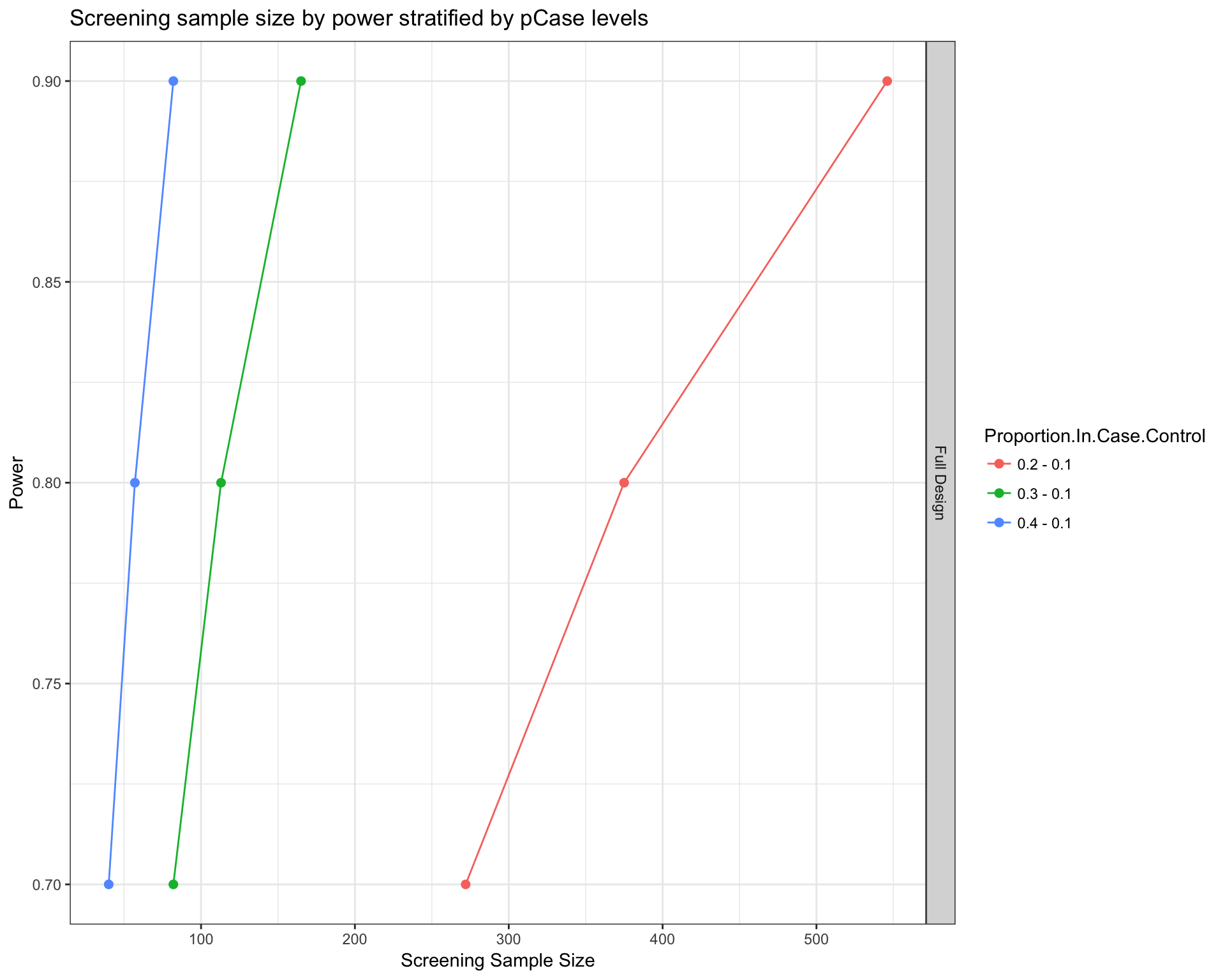
extra
Number of patients to be recruited to reach power
propPowerSampleSize(PTD_panel
, noPlot=FALSE
, alterationType = c("mutations", "copynumber")
, pCase = c(0.2, 0.3 , 0.4)
, pControl = rep(0.1, 3)
, power = c(0.7, 0.8, 0.9)
, alpha= 0.1
, side = 1
) 
propPowerSampleSize(PTD_panel
, var = "drug"
, alterationType = c("mutations", "copynumber")
, priority.trial = drugs
, priority.trial.order="optimal"
, noPlot=TRUE
, pCase = 0.3
, pControl = 0.1
, side =1
, alpha= 0.1
, power =0.8
, case.fraction = 0.6
)## $`pCase:0.3 | pControl:0.1 | Power:0.8`
## $`pCase:0.3 | pControl:0.1 | Power:0.8`$Summary
## Immune Checkpoint Inhibitor MET inhibitor HER2 inhibitor
## Screened 5976 0 0
## Eligible 65 89 89
## Not.Eligible 2967 0 0
## EGFR inhibitor ALK inhibitor BRAF inhibitor NOTCH inhibitor
## Screened 0 0 0 0
## Eligible 133 113 144 293
## Not.Eligible 0 0 0 0
## PARP inhibitor FGFR inhibitor AKT inhibitor Total
## Screened 0 0 0 5976
## Eligible 449 466 1173 3010
## Not.Eligible 0 0 0 2967
##
## $`pCase:0.3 | pControl:0.1 | Power:0.8`$Screening.scheme
## Immune Checkpoint Inhibitor MET inhibitor
## Immune Checkpoint Inhibitor 5976 5911
## MET inhibitor 0 0
## HER2 inhibitor 0 0
## EGFR inhibitor 0 0
## ALK inhibitor 0 0
## BRAF inhibitor 0 0
## NOTCH inhibitor 0 0
## PARP inhibitor 0 0
## FGFR inhibitor 0 0
## AKT inhibitor 0 0
## HER2 inhibitor EGFR inhibitor ALK inhibitor
## Immune Checkpoint Inhibitor 5823 5734 5602
## MET inhibitor 0 0 0
## HER2 inhibitor 0 0 0
## EGFR inhibitor 0 0 0
## ALK inhibitor 0 0 0
## BRAF inhibitor 0 0 0
## NOTCH inhibitor 0 0 0
## PARP inhibitor 0 0 0
## FGFR inhibitor 0 0 0
## AKT inhibitor 0 0 0
## BRAF inhibitor NOTCH inhibitor PARP inhibitor
## Immune Checkpoint Inhibitor 5489 5346 5053
## MET inhibitor 0 0 0
## HER2 inhibitor 0 0 0
## EGFR inhibitor 0 0 0
## ALK inhibitor 0 0 0
## BRAF inhibitor 0 0 0
## NOTCH inhibitor 0 0 0
## PARP inhibitor 0 0 0
## FGFR inhibitor 0 0 0
## AKT inhibitor 0 0 0
## FGFR inhibitor AKT inhibitor
## Immune Checkpoint Inhibitor 4605 4139
## MET inhibitor 0 0
## HER2 inhibitor 0 0
## EGFR inhibitor 0 0
## ALK inhibitor 0 0
## BRAF inhibitor 0 0
## NOTCH inhibitor 0 0
## PARP inhibitor 0 0
## FGFR inhibitor 0 0
## AKT inhibitor 0 0
##
## $`pCase:0.3 | pControl:0.1 | Power:0.8`$Allocation.scheme
## Immune Checkpoint Inhibitor MET inhibitor
## Immune Checkpoint Inhibitor 65 89
## MET inhibitor 0 0
## HER2 inhibitor 0 0
## EGFR inhibitor 0 0
## ALK inhibitor 0 0
## BRAF inhibitor 0 0
## NOTCH inhibitor 0 0
## PARP inhibitor 0 0
## FGFR inhibitor 0 0
## AKT inhibitor 0 0
## Total 65 89
## HER2 inhibitor EGFR inhibitor ALK inhibitor
## Immune Checkpoint Inhibitor 89 133 113
## MET inhibitor 0 0 0
## HER2 inhibitor 0 0 0
## EGFR inhibitor 0 0 0
## ALK inhibitor 0 0 0
## BRAF inhibitor 0 0 0
## NOTCH inhibitor 0 0 0
## PARP inhibitor 0 0 0
## FGFR inhibitor 0 0 0
## AKT inhibitor 0 0 0
## Total 89 133 113
## BRAF inhibitor NOTCH inhibitor PARP inhibitor
## Immune Checkpoint Inhibitor 144 293 449
## MET inhibitor 0 0 0
## HER2 inhibitor 0 0 0
## EGFR inhibitor 0 0 0
## ALK inhibitor 0 0 0
## BRAF inhibitor 0 0 0
## NOTCH inhibitor 0 0 0
## PARP inhibitor 0 0 0
## FGFR inhibitor 0 0 0
## AKT inhibitor 0 0 0
## Total 144 293 449
## FGFR inhibitor AKT inhibitor
## Immune Checkpoint Inhibitor 466 1173
## MET inhibitor 0 0
## HER2 inhibitor 0 0
## EGFR inhibitor 0 0
## ALK inhibitor 0 0
## BRAF inhibitor 0 0
## NOTCH inhibitor 0 0
## PARP inhibitor 0 0
## FGFR inhibitor 0 0
## AKT inhibitor 0 0
## Total 466 1173
##
## $`pCase:0.3 | pControl:0.1 | Power:0.8`$Probability.scheme
## Immune Checkpoint Inhibitor MET inhibitor
## Immune Checkpoint Inhibitor 0.01087745 0.01502933
## MET inhibitor 0.00000000 0.00000000
## HER2 inhibitor 0.00000000 0.00000000
## EGFR inhibitor 0.00000000 0.00000000
## ALK inhibitor 0.00000000 0.00000000
## BRAF inhibitor 0.00000000 0.00000000
## NOTCH inhibitor 0.00000000 0.00000000
## PARP inhibitor 0.00000000 0.00000000
## FGFR inhibitor 0.00000000 0.00000000
## AKT inhibitor 0.00000000 0.00000000
## HER2 inhibitor EGFR inhibitor ALK inhibitor
## Immune Checkpoint Inhibitor 0.01525865 0.02305367 0.02011605
## MET inhibitor 0.00000000 0.00000000 0.00000000
## HER2 inhibitor 0.00000000 0.00000000 0.00000000
## EGFR inhibitor 0.00000000 0.00000000 0.00000000
## ALK inhibitor 0.00000000 0.00000000 0.00000000
## BRAF inhibitor 0.00000000 0.00000000 0.00000000
## NOTCH inhibitor 0.00000000 0.00000000 0.00000000
## PARP inhibitor 0.00000000 0.00000000 0.00000000
## FGFR inhibitor 0.00000000 0.00000000 0.00000000
## AKT inhibitor 0.00000000 0.00000000 0.00000000
## BRAF inhibitor NOTCH inhibitor PARP inhibitor
## Immune Checkpoint Inhibitor 0.02605606 0.05472233 0.08876501
## MET inhibitor 0.00000000 0.00000000 0.00000000
## HER2 inhibitor 0.00000000 0.00000000 0.00000000
## EGFR inhibitor 0.00000000 0.00000000 0.00000000
## ALK inhibitor 0.00000000 0.00000000 0.00000000
## BRAF inhibitor 0.00000000 0.00000000 0.00000000
## NOTCH inhibitor 0.00000000 0.00000000 0.00000000
## PARP inhibitor 0.00000000 0.00000000 0.00000000
## FGFR inhibitor 0.00000000 0.00000000 0.00000000
## AKT inhibitor 0.00000000 0.00000000 0.00000000
## FGFR inhibitor AKT inhibitor
## Immune Checkpoint Inhibitor 0.1011765 0.2832461
## MET inhibitor 0.0000000 0.0000000
## HER2 inhibitor 0.0000000 0.0000000
## EGFR inhibitor 0.0000000 0.0000000
## ALK inhibitor 0.0000000 0.0000000
## BRAF inhibitor 0.0000000 0.0000000
## NOTCH inhibitor 0.0000000 0.0000000
## PARP inhibitor 0.0000000 0.0000000
## FGFR inhibitor 0.0000000 0.0000000
## AKT inhibitor 0.0000000 0.0000000
##
## $`pCase:0.3 | pControl:0.1 | Power:0.8`$Base.probabilities
## Immune Checkpoint Inhibitor MET inhibitor
## 0.01087745 0.01559101
## HER2 inhibitor EGFR inhibitor
## 0.01631617 0.02429297
## ALK inhibitor BRAF inhibitor
## 0.02501813 0.02900653
## NOTCH inhibitor PARP inhibitor
## 0.05873822 0.09209572
## FGFR inhibitor AKT inhibitor
## 0.11131255 0.27846265surv2 <- survPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, HR = 0.66
, power = 0.8
, alpha = 0.05
, case.fraction = 0.5
, ber=0.85
, fu=1.883
#, priority.trial.order="as.is"
, priority.trial.order="optimal"
, var = "drug"
, noPlot=TRUE)
kable(surv2 , row.names=FALSE)| Var | ScreeningSampleSize | EligibleSampleSize | Beta | Power | HazardRatio |
|---|---|---|---|---|---|
| AKT inhibitor | 902 | 251 | 0.2 | 0.8 | 0.66 |
| ALK inhibitor | 10033 | 251 | 0.2 | 0.8 | 0.66 |
| BRAF inhibitor | 8654 | 251 | 0.2 | 0.8 | 0.66 |
| EGFR inhibitor | 10333 | 251 | 0.2 | 0.8 | 0.66 |
| FGFR inhibitor | 2255 | 251 | 0.2 | 0.8 | 0.66 |
| HER2 inhibitor | 15384 | 251 | 0.2 | 0.8 | 0.66 |
| Immune Checkpoint Inhibitor | 23076 | 251 | 0.2 | 0.8 | 0.66 |
| MET inhibitor | 16100 | 251 | 0.2 | 0.8 | 0.66 |
| no_drug | 1588 | 251 | 0.2 | 0.8 | 0.66 |
| NOTCH inhibitor | 4274 | 251 | 0.2 | 0.8 | 0.66 |
| PARP inhibitor | 2726 | 251 | 0.2 | 0.8 | 0.66 |
| Full Design | 417 | 251 | 0.2 | 0.8 | 0.66 |
For the Abstract
PFS 2 samples calculations
Perform a 1-side 2-sample sample size calculation for PFS study using:
- fu 1.883
- case.fraction = 0.5
- ber = 0.85
- HR = 0.625
- power = 0.8
NOT OPTIMAL
library(parallel)
set.seed(111)
# NOT optimal
surv2 <- mclapply(1:100 , function(x){
out <- survPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, HR = 0.625
, power = 0.8
, alpha = 0.05
, case.fraction = 0.5
, ber=0.85
, fu=1.883
, var = "drug"
, side = 1
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE)
out <- out[ order(out$Var) , ]
return(out)
} , mc.cores=detectCores())
Screenings <- sapply(surv2 , function(x) x$ScreeningSampleSize)
medianScreening <- apply(Screenings , 1 , function(x) {
paste(median(x)
, paste0( "(" , quantile(x , 0.025)
, "-"
, quantile(x , 0.975) , ")"))
})
surv2DF <- data.frame(Var = surv2[[1]]$Var
, ScreeningSampleSize = medianScreening
, EligibleSampleSize = surv2[[1]]$EligibleSampleSize
, Beta = 0.2
, Power = 0.8
, HR = 0.625)
#export
#write.table(surv2, file = "~/Desktop/notoptimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(surv2DF[ match(c("Full Design" , drugs , "no_drug") , surv2DF$Var) , ] , row.names=FALSE)| Var | ScreeningSampleSize | EligibleSampleSize | Beta | Power | HR |
|---|---|---|---|---|---|
| Full Design | 249 (244-253) | 157 | 0.2 | 0.8 | 0.625 |
| HER2 inhibitor | 9352 (7809.075-11480.825) | 157 | 0.2 | 0.8 | 0.625 |
| PARP inhibitor | 1849.5 (1732.425-2023.2) | 157 | 0.2 | 0.8 | 0.625 |
| AKT inhibitor | 539.5 (526-556.525) | 157 | 0.2 | 0.8 | 0.625 |
| EGFR inhibitor | 6461 (5625.25-7482.825) | 157 | 0.2 | 0.8 | 0.625 |
| FGFR inhibitor | 1720 (1615.125-1833.575) | 157 | 0.2 | 0.8 | 0.625 |
| ALK inhibitor | 5384 (4913-6006.85) | 157 | 0.2 | 0.8 | 0.625 |
| BRAF inhibitor | 4023 (3524.225-4548.45) | 157 | 0.2 | 0.8 | 0.625 |
| MET inhibitor | 10452 (8770.075-13161) | 157 | 0.2 | 0.8 | 0.625 |
| NOTCH inhibitor | 3276 (2995-3526.45) | 157 | 0.2 | 0.8 | 0.625 |
| Immune Checkpoint Inhibitor | 13326 (10878-16535.4) | 157 | 0.2 | 0.8 | 0.625 |
| no_drug | 735 (704.475-761.525) | 157 | 0.2 | 0.8 | 0.625 |
- Median Number of patients necessary with CI: 56718 (52651.95-60975.85)
PRIORITY OPTIMAL
set.seed(112)
simulSurv2 <- mclapply(1:100 , function(x) {
survPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, HR = 0.625
, power = 0.8
, alpha = 0.05
, ber=0.85
, fu=1.883
, case.fraction = 0.5
, collapseByGene=TRUE
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, var = "drug"
, noPlot=TRUE
, side = 1
, priority.trial=drugs
, priority.trial.order="optimal")$`HR:0.625 | HR0:1 | Power:0.8`$Summary
} , mc.cores=detectCores())
summaryMat2 <- simulSurv2[[1]]
for(i in rownames(summaryMat2)){
for(j in colnames(summaryMat2)){
vec <- sapply(simulSurv2 , function(x) x[i , j])
summaryMat2[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat2, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(summaryMat2)| Immune Checkpoint Inhibitor | MET inhibitor | HER2 inhibitor | EGFR inhibitor | ALK inhibitor | BRAF inhibitor | NOTCH inhibitor | PARP inhibitor | FGFR inhibitor | AKT inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 13161 (351.3-15911) | 0 (0-12563.75) | 0 (0-405.299999999999) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 13495 (11198.9-15911) |
| Eligible | 157 (157-166.05) | 186 (157-241.3) | 202 (158.475-261.825) | 297.5 (222.9-390.825) | 282.5 (223.375-368.925) | 419 (338.75-538.825) | 515 (404.325-652.925) | 906.5 (758.65-1119.525) | 863 (712.9-1071.25) | 2789 (2330.8-3396.35) | 6620 (5533.25-7876.7) |
| Not.Eligible | 6676 (177.7-8052.1) | 0 (0-6299.925) | 0 (0-204.649999999999) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 6783 (5668.675-8069.75) |
Number of patients necessary under optimal design (median value with CI): 13495 (11198.9-15911)
Basically the number of samples screened for Immune check inhibitor, that is targetable only in a very small number of patients, is sufficient to cover all the other drugs in most of the cases.
The percentage of samples saved from passing from a non optimal (all drugs separated) to an optimal design (all drugs evaluated together) is 76.21%
PRIORITY NON OPTIMAL
Extract drug frequencies
drugFreqs <- coverageStackPlot(PTD_panel
, alterationType = c("mutations", "copynumber")
, var = "drug"
, grouping = NA
, tumor.freqs = c(brca=brca_freq
, luad=luad_freq
, lusc=lusc_freq
, stad = stad_freq
, coadread = coadread_freq)
, noPlot=TRUE)$plottedTable[1, ]
# Sort from highest to lowest
drugFreqs <- sort(drugFreqs , decreasing = TRUE)
# Remove no_drug
drugFreqs <- drugFreqs[ names(drugFreqs)!="no_drug"]Perform a priority trial starting from the drug with the highest frequency (NON OPTIMAL)
set.seed(112)
simulSurv2_NO <- mclapply(1:100 , function(x) {
survPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, HR = 0.625
, power = 0.8
, alpha = 0.05
, ber=0.85
, fu=1.883
, case.fraction = 0.5
, collapseByGene=TRUE
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, var = "drug"
, noPlot=TRUE
, side = 1
, priority.trial=names(drugFreqs)
, priority.trial.order="as.is")$`HR:0.625 | HR0:1 | Power:0.8`$Summary
} , mc.cores=detectCores())
summaryMat2_NO <- simulSurv2_NO[[1]]
for(i in rownames(summaryMat2_NO)){
for(j in colnames(summaryMat2_NO)){
vec <- sapply(simulSurv2_NO , function(x) x[i , j])
summaryMat2_NO[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat2_NO, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(summaryMat2_NO)| AKT inhibitor | FGFR inhibitor | PARP inhibitor | NOTCH inhibitor | BRAF inhibitor | ALK inhibitor | EGFR inhibitor | HER2 inhibitor | MET inhibitor | Immune Checkpoint Inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 541 (522.95-557) | 1334 (1206.025-1474.575) | 648 (515.35-824.125) | 2183.5 (1790.925-2585.175) | 849.5 (265.825-1552.425) | 3376 (2693.125-4211.8) | 1442 (261.475-2874.375) | 5739.5 (3686.925-7532.775) | 4033.5 (1548.35-6700.425) | 7713 (4890.225-11514) | 28259 (25198.8-32172.175) |
| Eligible | 8030 (7042.475-9051.775) | 1862.5 (1592.55-2148.15) | 1503.5 (1275.95-1795.575) | 634 (538.325-783.025) | 726.5 (605.5-878.675) | 364 (305.8-448.05) | 395.5 (326.85-477.975) | 225 (203-266.575) | 204 (183-238.2) | 157 (157-157) | 13982 (12498.35-16005.2) |
| Not.Eligible | 273 (260.425-285) | 673 (605.85-752.625) | 329 (259.275-411.1) | 1108.5 (905.85-1307.875) | 422 (135.175-784.849999999999) | 1686 (1350.8-2133.175) | 725 (131.95-1440.15) | 2903 (1834.875-3848.275) | 2018.5 (773.35-3422.45) | 7622 (4823.125-11406.775) | 18003.5 (15495.9-21489.85) |
Number of patients necessary under non optimal priority design (median value with CI): 28259 (25198.8-32172.175)
FULL SUMMARY OF THE THREE METHODS
Create a dataframe with median and CI for the three methods
pfs2 <- data.frame( Method = c("Indipendent" , "Priority Non Optimal" , "Priority Optimal")
, Median = c(median(n_patients_notoptimal)
, median(n_patients_optimal_NO)
, median(n_patients_optimal))
, CI_low = c(quantile(n_patients_notoptimal , 0.025)
, quantile(n_patients_optimal_NO , 0.025)
, quantile(n_patients_optimal , 0.025))
, CI_high = c(quantile(n_patients_notoptimal , 0.975)
, quantile(n_patients_optimal_NO , 0.975)
, quantile(n_patients_optimal , 0.975)))Plot as barplot
gpfs2 <- ggplot(pfs2, aes(x=Method, y=Median)) +
geom_bar(position=position_dodge(), stat="identity"
, fill = c("firebrick3" , "deepskyblue4" , "seagreen4")
, col=rep("black",3)) +
geom_errorbar(aes(ymin=CI_low, ymax=CI_high)
, width=.2
, position=position_dodge(.9)
, size=0.2
)
gpfs2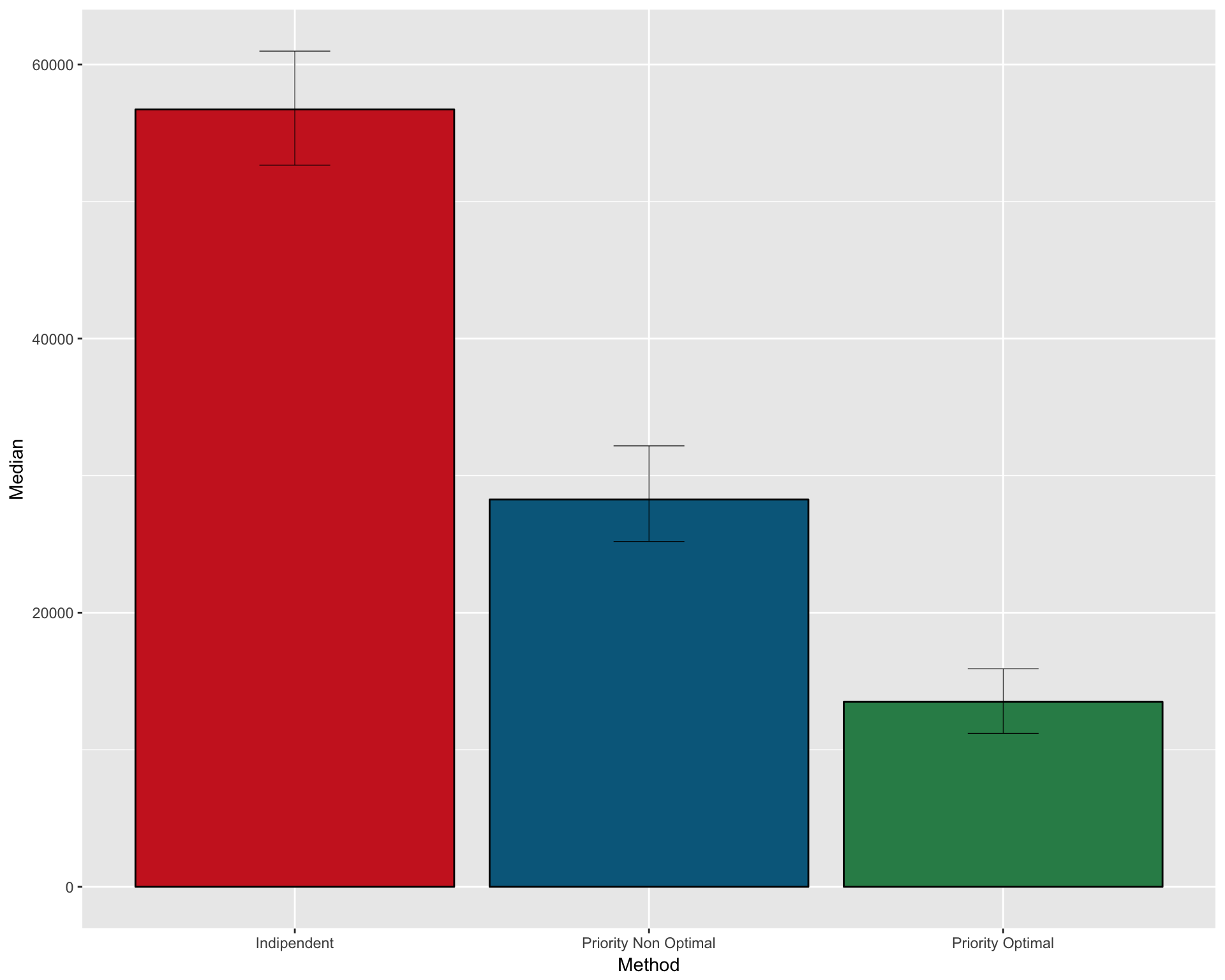
ggsave(filename="version_6.0/Figures/fig5A.svg", plot=gpfs2, device = "svg")## Saving 10 x 8 in imagePFS 1 sample calculations
Perform a 1-side 1-sample sample size calculation for PFS study using:
- MED0 = 0.8154673 (corresponding to ber = 0.85)
- MED1 = 1.304748 (corresponding to MED0/HR)
- power = 0.8
- fu = 1.883
NOT OPTIMAL
set.seed(111)
# NOT optimal
surv3 <- mclapply(1:100 , function(x){
out <- survPowerSampleSize1Arm(PTD_panel
, alterationType = c("mutations", "copynumber")
, MED0 = 0.8154673
, MED1 = 1.304748
, power = 0.8
, alpha = 0.05
, fu = 1.883
, var = "drug"
, side = 1
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE)
out <- out[ order(out$Var) , ]
return(out)
} , mc.cores=detectCores())
Screenings <- sapply(surv3 , function(x) x$ScreeningSampleSize)
medianScreening <- apply(Screenings , 1 , function(x) {
paste(median(x)
, paste0( "(" , quantile(x , 0.025)
, "-"
, quantile(x , 0.975) , ")"))
})
surv3DF <- data.frame(Var = surv3[[1]]$Var
, ScreeningSampleSize = medianScreening
, EligibleSampleSize = surv3[[1]]$EligibleSampleSize
, Beta = 0.2
, Power = 0.8
, MED1 = 1.304748)
#export
#write.table(surv3, file = "~/Desktop/notoptimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(surv3DF[ match(c("Full Design" , drugs , "no_drug") , surv3DF$Var) , ] , row.names=FALSE)| Var | ScreeningSampleSize | EligibleSampleSize | Beta | Power | MED1 |
|---|---|---|---|---|---|
| Full Design | 64 (63-65) | 40 | 0.2 | 0.8 | 1.304748 |
| HER2 inhibitor | 2322 (2026.725-2815.75) | 40 | 0.2 | 0.8 | 1.304748 |
| PARP inhibitor | 477.5 (443-517.575) | 40 | 0.2 | 0.8 | 1.304748 |
| AKT inhibitor | 138 (134-143) | 40 | 0.2 | 0.8 | 1.304748 |
| EGFR inhibitor | 1637 (1456.8-1999.45) | 40 | 0.2 | 0.8 | 1.304748 |
| FGFR inhibitor | 442.5 (412.9-472.05) | 40 | 0.2 | 0.8 | 1.304748 |
| ALK inhibitor | 1393 (1243.375-1580) | 40 | 0.2 | 0.8 | 1.304748 |
| BRAF inhibitor | 1022 (911.85-1146.725) | 40 | 0.2 | 0.8 | 1.304748 |
| MET inhibitor | 2703 (2311.025-3196) | 40 | 0.2 | 0.8 | 1.304748 |
| NOTCH inhibitor | 839 (764.425-945.4) | 40 | 0.2 | 0.8 | 1.304748 |
| Immune Checkpoint Inhibitor | 3438 (2814.25-4348.225) | 40 | 0.2 | 0.8 | 1.304748 |
| no_drug | 187 (180.475-194) | 40 | 0.2 | 0.8 | 1.304748 |
- Median Number of patients necessary with CI: 14460 (13541.42-15790.52)
OPTIMAL
set.seed(112)
simulSurv3 <- mclapply(1:100 , function(x) {
survPowerSampleSize1Arm(PTD_panel
, alterationType = c("mutations", "copynumber")
, MED0 = 0.8154673
, MED1 = 1.304748
, power = 0.8
, alpha = 0.05
, fu = 1.883
, var = "drug"
, side = 1
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE
, priority.trial=drugs
, priority.trial.order="optimal")$`MED1:1.304748 | MED0:0.8154673 | Power:0.8`$Summary
} , mc.cores=detectCores())
summaryMat3 <- simulSurv3[[1]]
for(i in rownames(summaryMat3)){
for(j in colnames(summaryMat3)){
vec <- sapply(simulSurv3 , function(x) x[i , j])
summaryMat3[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat3, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(summaryMat3)| Immune Checkpoint Inhibitor | MET inhibitor | HER2 inhibitor | EGFR inhibitor | ALK inhibitor | BRAF inhibitor | NOTCH inhibitor | PARP inhibitor | FGFR inhibitor | AKT inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 3354 (1534.225-4149.075) | 0 (0-1611.17499999998) | 0 (0-19.4249999999997) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 3374.5 (2962.95-4149.075) |
| Eligible | 40 (40-43) | 48.5 (40-65) | 53 (40.95-66.575) | 77.5 (60-99.05) | 73 (57.95-91.05) | 105.5 (87.475-135.575) | 133.5 (111.475-163.575) | 229.5 (190.95-291.575) | 220 (181.95-272.575) | 707 (622.425-872.975) | 1684.5 (1476.475-2050.475) |
| Not.Eligible | 1697 (770-2108.675) | 0 (0-804.649999999989) | 0 (0-9.97499999999984) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 1708 (1471.8-2108.675) |
Number of patients necessary under optimal design (median value with CI): 3374.5 (2962.95-4149.075)
Basically the number of samples screened for Immune check inhibitor, that is targetable only in a very small number of patients, is sufficient to cover all the other drugs in most of the cases.
The percentage of samples saved from passing from a non optimal (all drugs separated) to an optimal design (all drugs evaluated together) is 76.66%
PRIORITY NON OPTIMAL
Perform a priority trial starting from the drug with the highest frequency (NON OPTIMAL)
set.seed(112)
simulSurv3_NO <- mclapply(1:100 , function(x) {
survPowerSampleSize1Arm(PTD_panel
, alterationType = c("mutations", "copynumber")
, MED0 = 0.8154673
, MED1 = 1.304748
, power = 0.8
, alpha = 0.05
, fu = 1.883
, var = "drug"
, side = 1
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot)
, noPlot=TRUE
, priority.trial=names(drugFreqs)
, priority.trial.order="as.is")$`MED1:1.304748 | MED0:0.8154673 | Power:0.8`$Summary
} , mc.cores=detectCores())
summaryMat3_NO <- simulSurv3_NO[[1]]
for(i in rownames(summaryMat3_NO)){
for(j in colnames(summaryMat3_NO)){
vec <- sapply(simulSurv3_NO , function(x) x[i , j])
summaryMat3_NO[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat3, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(summaryMat3_NO)| AKT inhibitor | FGFR inhibitor | PARP inhibitor | NOTCH inhibitor | BRAF inhibitor | ALK inhibitor | EGFR inhibitor | HER2 inhibitor | MET inhibitor | Immune Checkpoint Inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 138 (134-143.525) | 340 (309.475-374.675) | 170 (128.85-221) | 556 (457.475-657.825) | 242 (90.45-371) | 866.5 (647.775-1069.025) | 395.5 (98.25-676) | 1474.5 (1110.325-1893.775) | 978.5 (370.475-1761.675) | 2060.5 (1274.95-3186.1) | 7190.5 (6298-8532.275) |
| Eligible | 2024 (1745.475-2386.65) | 477 (408-568) | 383.5 (338.375-465.35) | 167.5 (138.375-190.1) | 185 (154-226.15) | 92.5 (77-115.525) | 101 (82.95-129.675) | 58 (52-66) | 53 (47-62) | 40 (40-40) | 3567 (3132.75-4229.2) |
| Not.Eligible | 70 (67-74) | 172 (155-188.525) | 86 (65.475-112.575) | 278 (229.95-334.675) | 121 (45.75-190.05) | 439 (326.025-537.875) | 199 (50.575-338.575) | 744.5 (555.95-966.25) | 500.5 (187.05-882.575) | 2036 (1257.95-3155.05) | 4596.5 (3902.35-5812.125) |
Number of patients necessary under non optimal priority design (median value with CI): 7190.5 (6298-8532.275)
FULL SUMMARY OF THE THREE METHODS
Create a dataframe with median and CI for the three methods
pfs1 <- data.frame( Method = c("Indipendent" , "Priority Non Optimal" , "Priority Optimal")
, Median = c(median(n_patients_notoptimal)
, median(n_patients_optimal_NO)
, median(n_patients_optimal))
, CI_low = c(quantile(n_patients_notoptimal , 0.025)
, quantile(n_patients_optimal_NO , 0.025)
, quantile(n_patients_optimal , 0.025))
, CI_high = c(quantile(n_patients_notoptimal , 0.975)
, quantile(n_patients_optimal_NO , 0.975)
, quantile(n_patients_optimal , 0.975)))
kable(pfs1)| Method | Median | CI_low | CI_high |
|---|---|---|---|
| Indipendent | 14459.5 | 13541.42 | 15790.525 |
| Priority Non Optimal | 7190.5 | 6298.00 | 8532.275 |
| Priority Optimal | 3374.5 | 2962.95 | 4149.075 |
Plot as barplot
gpfs1 <- ggplot(pfs1, aes(x=Method, y=Median)) +
geom_bar(position=position_dodge(), stat="identity"
, fill = c("firebrick3" , "deepskyblue4" , "seagreen4")
, col=rep("black",3)) +
geom_errorbar(aes(ymin=CI_low, ymax=CI_high)
, width=.2
, position=position_dodge(.9)
, size=0.2
)
gpfs1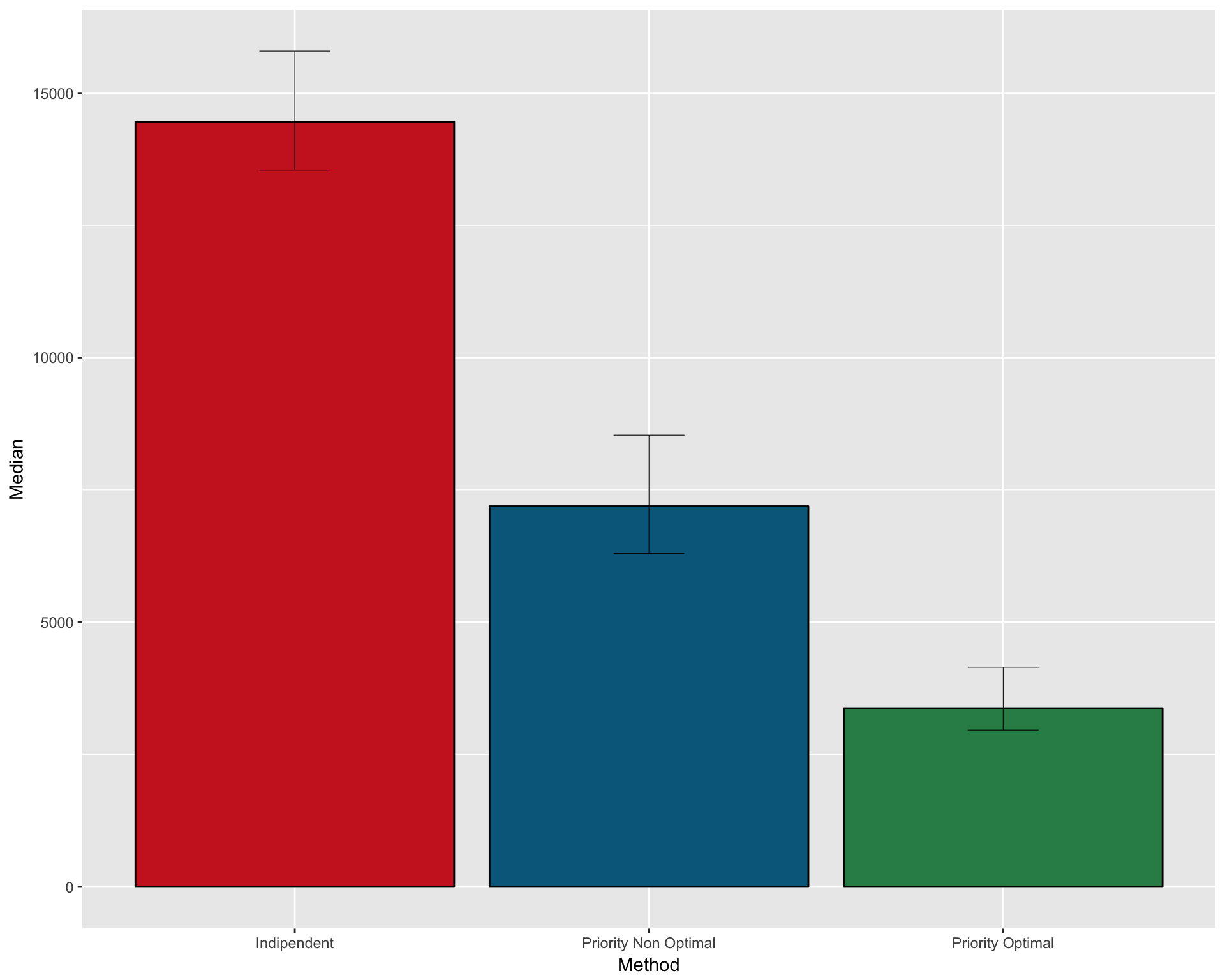
ggsave(filename="version_6.0/Figures/fig5B.svg", plot=gpfs1, device = "svg")## Saving 10 x 8 in imageProportion trial 2-sample
Perform a 1-side 2-sample sample size calculation for difference in proportion with:
- pCase = 0.4
- pControl = 0.1
- case.fraction = 0.5
- power = 0.8
NOT OPTIMAL
set.seed(111)
# NOT optimal
prop2 <- mclapply(1:100 , function(x){
out <- propPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, pCase = 0.4
, pControl = 0.1
, power = 0.8
, case.fraction = 0.5
, type = "chisquare"
, var = "drug"
, side = 1
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE)
out <- out[ order(out$Var) , ]
return(out)
} , mc.cores=detectCores())
Screenings <- sapply(prop2 , function(x) x$ScreeningSampleSize)
medianScreening <- apply(Screenings , 1 , function(x) {
paste(median(x)
, paste0( "(" , quantile(x , 0.025)
, "-"
, quantile(x , 0.975) , ")"))
})
prop2DF <- data.frame(Var = prop2[[1]]$Var
, ScreeningSampleSize = medianScreening
, EligibleSampleSize = prop2[[1]]$EligibleSampleSize
, Beta = 0.2
, Power = 0.8
, Proportion.In.Case.Control = "0.4 - 0.1")
#export
#write.table(surv2, file = "~/Desktop/notoptimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(prop2DF[ match(c("Full Design" , drugs , "no_drug") , prop2DF$Var) , ] , row.names=FALSE)| Var | ScreeningSampleSize | EligibleSampleSize | Beta | Power | Proportion.In.Case.Control |
|---|---|---|---|---|---|
| Full Design | 73 (72-75) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| HER2 inhibitor | 2670 (2314-3157.6) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| PARP inhibitor | 550.5 (506.85-594.525) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| AKT inhibitor | 159 (153-165) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| EGFR inhibitor | 1899 (1684.275-2192.875) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| FGFR inhibitor | 499 (478.425-542.775) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| ALK inhibitor | 1610 (1427-1861.1) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| BRAF inhibitor | 1170 (1029.425-1297) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| MET inhibitor | 3063 (2613.45-3635.1) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| NOTCH inhibitor | 971 (868.375-1060.025) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| Immune Checkpoint Inhibitor | 3857 (3219.35-5000) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
| no_drug | 216 (209.475-224) | 46 | 0.2 | 0.8 | 0.4 - 0.1 |
- Median Number of patients necessary with CI: 16476 (15482.2-18165.57)
OPTIMAL
set.seed(112)
simulprop2 <- mclapply(1:100 , function(x) {
propPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, pCase = 0.4
, pControl = 0.1
, power = 0.8
, case.fraction = 0.5
, var = "drug"
, type = "chisquare"
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE
, priority.trial=drugs
, priority.trial.order="optimal")$`pCase:0.4 | pControl:0.1 | Power:0.8`$Summary
} , mc.cores=detectCores())
prop2summaryMat2 <- simulprop2[[1]]
for(i in rownames(prop2summaryMat2)){
for(j in colnames(prop2summaryMat2)){
vec <- sapply(simulprop2 , function(x) x[i , j])
prop2summaryMat2[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat2, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(prop2summaryMat2)| Immune Checkpoint Inhibitor | MET inhibitor | HER2 inhibitor | ALK inhibitor | EGFR inhibitor | BRAF inhibitor | NOTCH inhibitor | PARP inhibitor | FGFR inhibitor | AKT inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 5216.5 (339.4-6205.45) | 0 (0-4444.475) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 5251 (4425-6205.45) |
| Eligible | 58 (58-60.525) | 72 (58-97.2499999999999) | 81 (63.475-108.575) | 110 (86-135.05) | 117 (99-145.1) | 161.5 (132.95-208.2) | 204 (167.95-250.575) | 353.5 (302.95-431.625) | 335 (276.475-409.15) | 1098 (917.775-1321.025) | 2598.5 (2199.4-3083.525) |
| Not.Eligible | 2604 (171.125-3148.575) | 0 (0-2229.75) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 2641.5 (2225.4-3148.575) |
Number of patients necessary under optimal design (median value): 5251 (4425-6205.45)
Basically the number of samples screened for Immune check inhibitor, that is targetable only in a very small number of patients, is sufficient to cover all the other drugs in most of the cases.
The percentage of samples saved from passing from a non optimal (all drugs separated) to an optimal design (all drugs evaluated together) is 68.13%
PRIORITY NON OPTIMAL
Perform a priority trial starting from the drug with the highest frequency (NON OPTIMAL)
set.seed(112)
simulprop2_NO <- mclapply(1:100 , function(x) {
propPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, pCase = 0.4
, pControl = 0.1
, power = 0.8
, case.fraction = 0.5
, var = "drug"
, type = "chisquare"
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE
, priority.trial=names(drugFreqs)
, priority.trial.order="as.is")$`pCase:0.4 | pControl:0.1 | Power:0.8`$Summary
} , mc.cores=detectCores())
prop2summaryMat2_NO <- simulprop2_NO[[1]]
for(i in rownames(prop2summaryMat2_NO)){
for(j in colnames(prop2summaryMat2_NO)){
vec <- sapply(simulprop2_NO , function(x) x[i , j])
prop2summaryMat2_NO[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat3, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(prop2summaryMat2_NO)| AKT inhibitor | FGFR inhibitor | PARP inhibitor | NOTCH inhibitor | BRAF inhibitor | ALK inhibitor | EGFR inhibitor | HER2 inhibitor | MET inhibitor | Immune Checkpoint Inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 200 (193.95-206) | 491 (444.225-530.525) | 251 (171.325-308.25) | 804.5 (662.025-986.175) | 340.5 (112.85-546) | 1232 (950.775-1628.025) | 583.5 (149.225-1170.5) | 2053.5 (1484.45-2710.15) | 1510 (616.9-2254.8) | 2974 (1865.025-4383.975) | 10430 (9256.7-12465.325) |
| Eligible | 2934 (2583.375-3480.975) | 698 (589.225-824.525) | 563 (476.9-662.575) | 240 (202.475-285.675) | 267.5 (225.95-326) | 135 (114-161.625) | 146 (119.475-180.05) | 84 (74.95-99) | 76 (68.475-90.625) | 58 (58-59) | 5182.5 (4577.85-6101.3) |
| Not.Eligible | 101 (96.475-106) | 246.5 (220.9-268.525) | 126.5 (87.425-155.625) | 405.5 (331.475-500.775) | 170.5 (57.425-277) | 616.5 (470.7-824.025) | 291.5 (75.825-584.625) | 1037 (746.5-1362.175) | 753.5 (313.35-1146.525) | 2939 (1840.55-4341.925) | 6619 (5584.175-8361.175) |
Number of patients necessary under non optimal priority design (median value with CI): 7190.5 (6298-8532.275)
FULL SUMMARY OF THE THREE METHODS
Create a dataframe with median and CI for the three methods
propd <- data.frame( Method = c("Indipendent" , "Priority Non Optimal" , "Priority Optimal")
, Median = c(median(n_patients_notoptimal)
, median(n_patients_optimal_NO)
, median(n_patients_optimal))
, CI_low = c(quantile(n_patients_notoptimal , 0.025)
, quantile(n_patients_optimal_NO , 0.025)
, quantile(n_patients_optimal , 0.025))
, CI_high = c(quantile(n_patients_notoptimal , 0.975)
, quantile(n_patients_optimal_NO , 0.975)
, quantile(n_patients_optimal , 0.975)))
kable(propd)| Method | Median | CI_low | CI_high |
|---|---|---|---|
| Indipendent | 16475.5 | 15482.2 | 18165.58 |
| Priority Non Optimal | 10430.0 | 9256.7 | 12465.33 |
| Priority Optimal | 5251.0 | 4425.0 | 6205.45 |
Plot as barplot
gpropd <- ggplot(propd, aes(x=Method, y=Median)) +
geom_bar(position=position_dodge(), stat="identity"
, fill = c("firebrick3" , "deepskyblue4" , "seagreen4")
, col=rep("black",3)) +
geom_errorbar(aes(ymin=CI_low, ymax=CI_high)
, width=.2
, position=position_dodge(.9)
, size=0.2
)
gpropd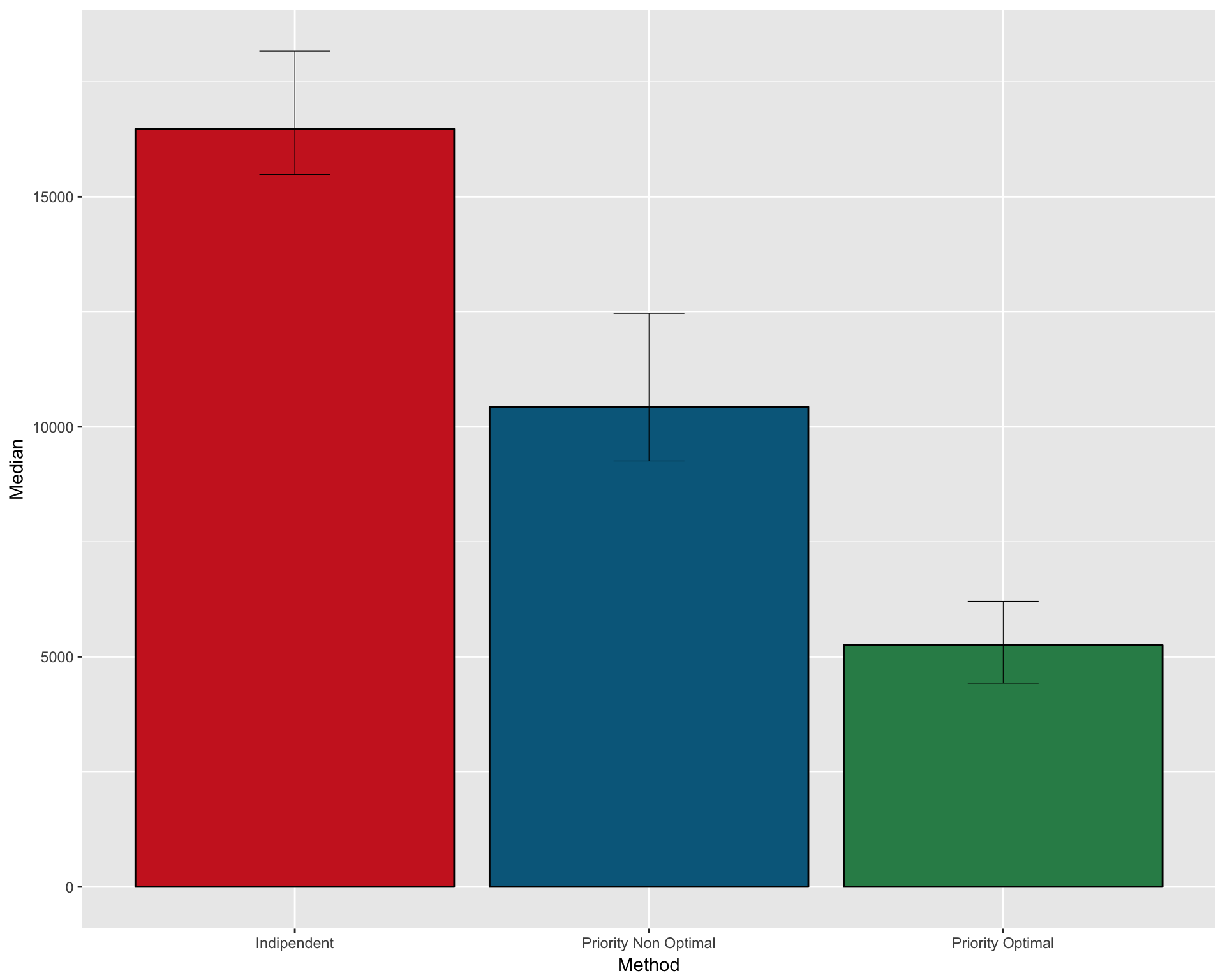
ggsave(filename="version_6.0/Figures/fig5C.svg", plot=gpropd, device = "svg")## Saving 10 x 8 in imageProportion trial 1-sample
Perform a 1-side 1-sample sample size calculation for difference in proportion with:
- pCase = 0.4
- pControl = 0.1
- power = 0.8
NOT OPTIMAL
set.seed(111)
# NOT optimal
prop3 <- mclapply(1:100 , function(x){
out <- propPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, pCase = 0.4
, pControl = 0.1
, power = 0.8
, type = "arcsin"
, var = "drug"
, side = 1
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE)
out <- out[ order(out$Var) , ]
return(out)
} , mc.cores=detectCores())
Screenings <- sapply(prop3 , function(x) x$ScreeningSampleSize)
medianScreening <- apply(Screenings , 1 , function(x) {
paste(median(x)
, paste0( "(" , quantile(x , 0.025)
, "-"
, quantile(x , 0.975) , ")"))
})
prop3DF <- data.frame(Var = prop3[[1]]$Var
, ScreeningSampleSize = medianScreening
, EligibleSampleSize = prop3[[1]]$EligibleSampleSize
, Beta = 0.2
, Power = 0.8
, Proportion.In.Case.Control = "0.4 - 0.1")
#export
#write.table(surv2, file = "~/Desktop/notoptimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(prop3DF[ match(c("Full Design" , drugs , "no_drug") , prop3DF$Var) , ] , row.names=FALSE)| Var | ScreeningSampleSize | EligibleSampleSize | Beta | Power | Proportion.In.Case.Control |
|---|---|---|---|---|---|
| Full Design | 21 (21-21) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| HER2 inhibitor | 775 (654.275-901) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| PARP inhibitor | 155 (146-166.525) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| AKT inhibitor | 45 (44-47) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| EGFR inhibitor | 532 (475.125-618) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| FGFR inhibitor | 144 (131-157.05) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| ALK inhibitor | 455 (402-505.15) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| BRAF inhibitor | 329.5 (294.8-377.2) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| MET inhibitor | 866 (720.85-1098.525) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| NOTCH inhibitor | 275 (249.475-301.575) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| Immune Checkpoint Inhibitor | 1104 (924.75-1360.05) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
| no_drug | 61 (59-63) | 13 | 0.2 | 0.8 | 0.4 - 0.1 |
- Median Number of patients necessary with CI: 4698 (4349.375-5085.925)
OPTIMAL
set.seed(112)
simulprop3 <- mclapply(1:100 , function(x) {
propPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, pCase = 0.4
, pControl = 0.1
, power = 0.8
, var = "drug"
, type = "arcsin"
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE
, priority.trial=drugs
, priority.trial.order="optimal")$`pCase:0.4 | pControl:0.1 | Power:0.8`$Summary
} , mc.cores=detectCores())
prop3summaryMat2 <- simulprop3[[1]]
for(i in rownames(prop3summaryMat2)){
for(j in colnames(prop3summaryMat2)){
vec <- sapply(simulprop3 , function(x) x[i , j])
prop3summaryMat2[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat2, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(prop3summaryMat2)| Immune Checkpoint Inhibitor | MET inhibitor | HER2 inhibitor | EGFR inhibitor | ALK inhibitor | BRAF inhibitor | NOTCH inhibitor | PARP inhibitor | FGFR inhibitor | AKT inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 1376 (60.875-1712.175) | 0 (0-1230.75) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 1396.5 (1146.375-1712.175) |
| Eligible | 16 (16-17.525) | 19 (16-27.525) | 22 (17-28) | 32 (25-40) | 30 (23-37.525) | 43.5 (35-55.525) | 54 (43-69.525) | 94 (79.475-120.05) | 88.5 (73-113.725) | 296.5 (239-364.05) | 696 (572.95-856.25) |
| Not.Eligible | 695 (31.175-864.05) | 0 (0-619.425) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 0 (0-0) | 698.5 (572.9-864.05) |
Number of patients necessary under optimal design (median value): 1396.5 (1146.375-1712.175)
Basically the number of samples screened for Immune check inhibitor, that is targetable only in a very small number of patients, is sufficient to cover all the other drugs in most of the cases.
The percentage of samples saved from passing from a non optimal (all drugs separated) to an optimal design (all drugs evaluated together) is 70.27%
PRIORITY NON OPTIMAL
Perform a priority trial starting from the drug with the highest frequency (NON OPTIMAL)
set.seed(112)
simulprop3_NO <- mclapply(1:100 , function(x) {
propPowerSampleSize(PTD_panel
, alterationType = c("mutations", "copynumber")
, pCase = 0.4
, pControl = 0.1
, power = 0.8
, var = "drug"
, type = "arcsin"
, tumor.weights = c(brca=brca_tot
, luad=luad_tot
, lusc=lusc_tot
, stad = stad_tot
, coadread = coadread_tot
)
, noPlot=TRUE
, priority.trial=names(drugFreqs)
, priority.trial.order="as.is")$`pCase:0.4 | pControl:0.1 | Power:0.8`$Summary
} , mc.cores=detectCores())
prop3summaryMat2_NO <- simulprop3_NO[[1]]
for(i in rownames(prop3summaryMat2_NO)){
for(j in colnames(prop3summaryMat2_NO)){
vec <- sapply(simulprop3_NO , function(x) x[i , j])
prop3summaryMat2_NO[i , j] <- paste(median(vec) ,
paste0( "(" , quantile(vec , 0.025)
, "-"
, quantile(vec , 0.975) , ")"))
}
}
#save
#write.table(summaryMat3, file = "~/Desktop/optimal_ptd-showcase.txt", quote=FALSE, sep=",")
#preview
kable(prop3summaryMat2_NO)| AKT inhibitor | FGFR inhibitor | PARP inhibitor | NOTCH inhibitor | BRAF inhibitor | ALK inhibitor | EGFR inhibitor | HER2 inhibitor | MET inhibitor | Immune Checkpoint Inhibitor | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Screened | 56 (53.475-58) | 137 (122.475-154) | 68.5 (48.475-82) | 223.5 (189.425-262.525) | 88.5 (21.425-148.05) | 339 (245.375-420.525) | 163.5 (28.325-316.725) | 563.5 (398.375-791.625) | 399 (211.425-657.1) | 810 (498.45-1215.95) | 2876 (2532.9-3428.65) |
| Eligible | 807.5 (697-984.05) | 187.5 (159-223.575) | 152 (132-182.1) | 67 (53.425-78) | 76 (62.475-88.525) | 38 (32-47.525) | 41 (32.475-50) | 24 (20-27) | 21 (19-25) | 16 (16-16) | 1423.5 (1254.375-1696.15) |
| Not.Eligible | 29 (27-30) | 70 (62-78) | 35 (24.475-41) | 113 (93.95-133.525) | 45 (10.95-74.525) | 171.5 (122.95-211.05) | 83.5 (14.9-160.05) | 286 (202.925-399.525) | 202 (105.475-333.2) | 800 (490.975-1204.9) | 1830.5 (1525.85-2281.95) |
Number of patients necessary under non optimal priority design (median value with CI): 2876 (2532.9-3428.65)
FULL SUMMARY OF THE THREE METHODS
Create a dataframe with median and CI for the three methods
propd1 <- data.frame( Method = c("Indipendent" , "Priority Non Optimal" , "Priority Optimal")
, Median = c(median(n_patients_notoptimal)
, median(n_patients_optimal_NO)
, median(n_patients_optimal))
, CI_low = c(quantile(n_patients_notoptimal , 0.025)
, quantile(n_patients_optimal_NO , 0.025)
, quantile(n_patients_optimal , 0.025))
, CI_high = c(quantile(n_patients_notoptimal , 0.975)
, quantile(n_patients_optimal_NO , 0.975)
, quantile(n_patients_optimal , 0.975)))
kable(propd1)| Method | Median | CI_low | CI_high |
|---|---|---|---|
| Indipendent | 4697.5 | 4349.375 | 5085.925 |
| Priority Non Optimal | 2876.0 | 2532.900 | 3428.650 |
| Priority Optimal | 1396.5 | 1146.375 | 1712.175 |
Plot as barplot
gpropd1 <- ggplot(propd1, aes(x=Method, y=Median)) +
geom_bar(position=position_dodge(), stat="identity"
, fill = c("firebrick3" , "deepskyblue4" , "seagreen4")
, col=rep("black",3)) +
geom_errorbar(aes(ymin=CI_low, ymax=CI_high)
, width=.2
, position=position_dodge(.9)
, size=0.2
)
gpropd1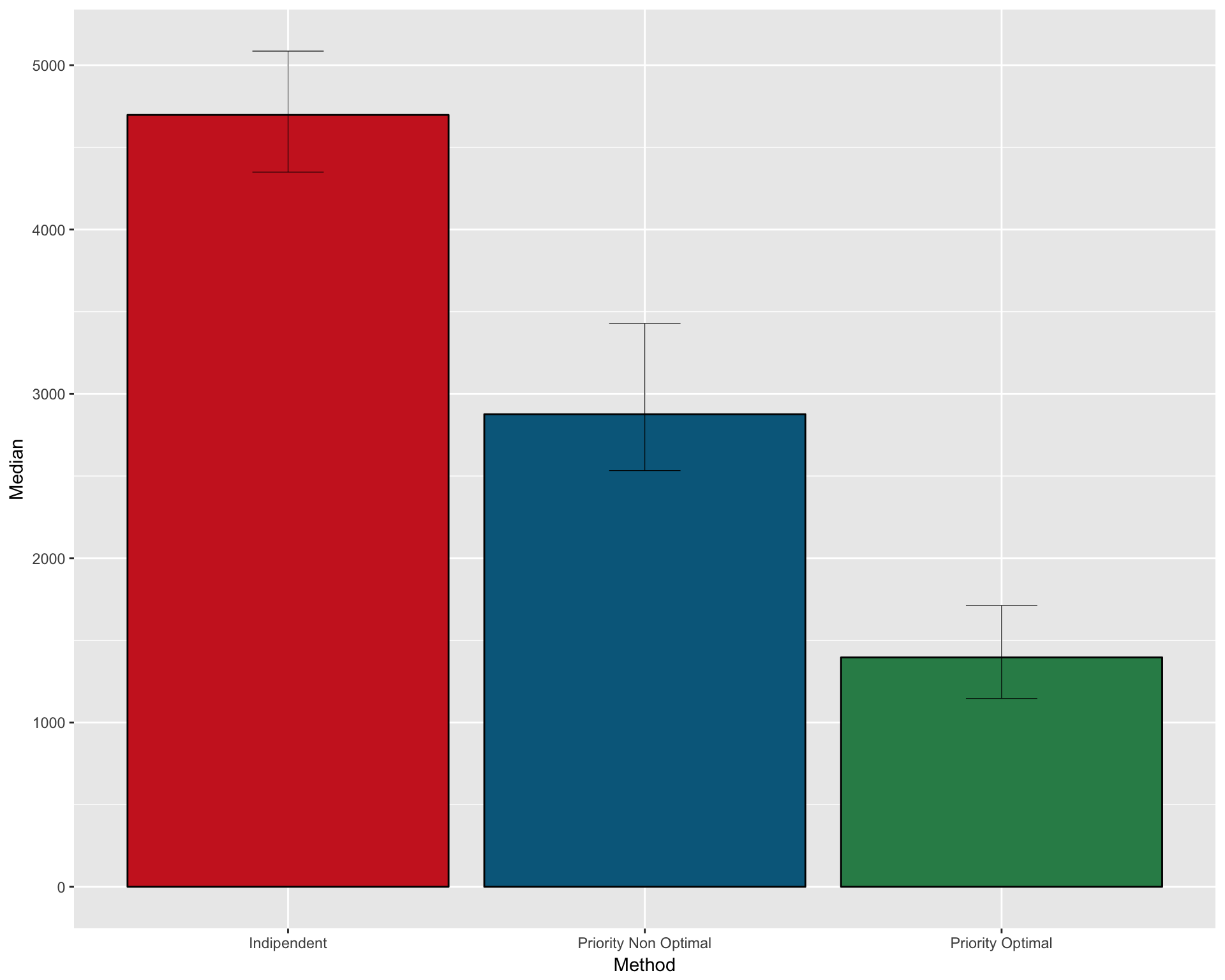
ggsave(filename="version_6.0/Figures/fig5D.svg", plot=gpropd1, device = "svg")## Saving 10 x 8 in imageOne figure for all
sampSizeMethods <- rbind(pfs2 , pfs1 , propd , propd1)
sampSizeMethods$Design <- rep(c("Survival 2 Sample" , "Survival 1 Sample" , "Proportion 2 Sample" , "Proportion 1 Sample")
, c(3,3,3,3))gsampSizeMethods <- ggplot(sampSizeMethods, aes(x=Design, y=Median , fill=Method)) +
geom_bar(position=position_dodge(), stat="identity" , color="black")+
scale_fill_manual(values=c("firebrick3" , "deepskyblue4" , "seagreen4"))+
geom_errorbar(aes(ymin=CI_low, ymax=CI_high)
, width=.2
, position=position_dodge(.9)
, size=0.2
)
gsampSizeMethods
ggsave(filename="version_6.0/Figures/fig3B.svg", plot=gsampSizeMethods, device = "svg")## Saving 10 x 8 in imageSession info
For reproducibility purpose:
sessionInfo()## R version 3.5.0 Patched (2018-06-01 r74839)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS High Sierra 10.13.3
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] parallel stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] gdtools_0.1.7 svglite_1.2.1
## [3] bindrcpp_0.2.2 readxl_1.1.0
## [5] ggplot2_2.2.1 DT_0.4
## [7] knitr_1.20 PrecisionTrialDrawer_0.99.0
## [9] BiocStyle_2.8.2
##
## loaded via a namespace (and not attached):
## [1] Biobase_2.40.0 httr_1.3.1
## [3] tidyr_0.8.1 bit64_0.9-7
## [5] jsonlite_1.5 shiny_1.1.0
## [7] assertthat_0.2.0 LowMACAAnnotation_0.99.3
## [9] highr_0.7 stats4_3.5.0
## [11] blob_1.1.1 GenomeInfoDbData_1.1.0
## [13] cellranger_1.1.0 yaml_2.1.19
## [15] progress_1.1.2 ggrepel_0.8.0
## [17] pillar_1.2.3 RSQLite_2.1.1
## [19] backports_1.1.2 glue_1.2.0
## [21] digest_0.6.15 GenomicRanges_1.32.3
## [23] RColorBrewer_1.1-2 promises_1.0.1
## [25] XVector_0.20.0 cgdsr_1.2.10
## [27] colorspace_1.3-2 htmltools_0.3.6
## [29] httpuv_1.4.3 R.oo_1.22.0
## [31] plyr_1.8.4 pkgconfig_2.0.1
## [33] XML_3.98-1.11 biomaRt_2.36.1
## [35] zlibbioc_1.26.0 purrr_0.2.5
## [37] xtable_1.8-2 scales_0.5.0
## [39] later_0.7.3 brglm_0.6.1
## [41] BiocParallel_1.14.1 tibble_1.4.2
## [43] IRanges_2.14.10 BiocGenerics_0.26.0
## [45] lazyeval_0.2.1 magrittr_1.5
## [47] mime_0.5 memoise_1.1.0
## [49] evaluate_0.10.1 R.methodsS3_1.7.1
## [51] tools_3.5.0 data.table_1.11.4
## [53] prettyunits_1.0.2 hms_0.4.2
## [55] stringr_1.3.1 googleVis_0.6.2
## [57] S4Vectors_0.18.3 munsell_0.5.0
## [59] AnnotationDbi_1.42.1 compiler_3.5.0
## [61] GenomeInfoDb_1.16.0 profileModel_0.5-9
## [63] rlang_0.2.1 grid_3.5.0
## [65] RCurl_1.95-4.10 htmlwidgets_1.2
## [67] crosstalk_1.0.0 bitops_1.0-6
## [69] shinyBS_0.61 labeling_0.3
## [71] rmarkdown_1.10 testthat_2.0.0
## [73] gtable_0.2.0 codetools_0.2-15
## [75] DBI_1.0.0 curl_3.2
## [77] reshape2_1.4.3 R6_2.2.2
## [79] dplyr_0.7.5 bit_1.1-14
## [81] bindr_0.1.1 rprojroot_1.3-2
## [83] readr_1.1.1 stringi_1.2.2
## [85] Rcpp_0.12.17 tidyselect_0.2.4Frequency is calculated on the the selected population for the study (i.e. frequency sum = 1) and not on the overall cancer population that includes all tumor types.↩
Frequency is calculated on the the selected population for the study (i.e. frequency sum = 1) and not on the overall cancer population that includes all tumor types.↩
Copyright © 2017 Giorgio Melloni. All rights reserved.